Текст или мультимодальность?
Как только мы начинаем закладывать в языковую модель большие объёмы текстовой информации, она учится воспроизводить эти знания, пытается комбинировать их внутри себя, отвечать и решать задачи, связанные с NLP.
Используя только языковую модель, можно решать широкий спектр задач. При этом картинки, видео- и аудиосообщения становятся естественной формой коммуникации. Если мы хотим создать качественный ассистент на базе искусственного интеллекта, надо уметь оперировать разными типами данных.
Что будет, если мы начнём учить языковую модель воспринимать другие типы данных?
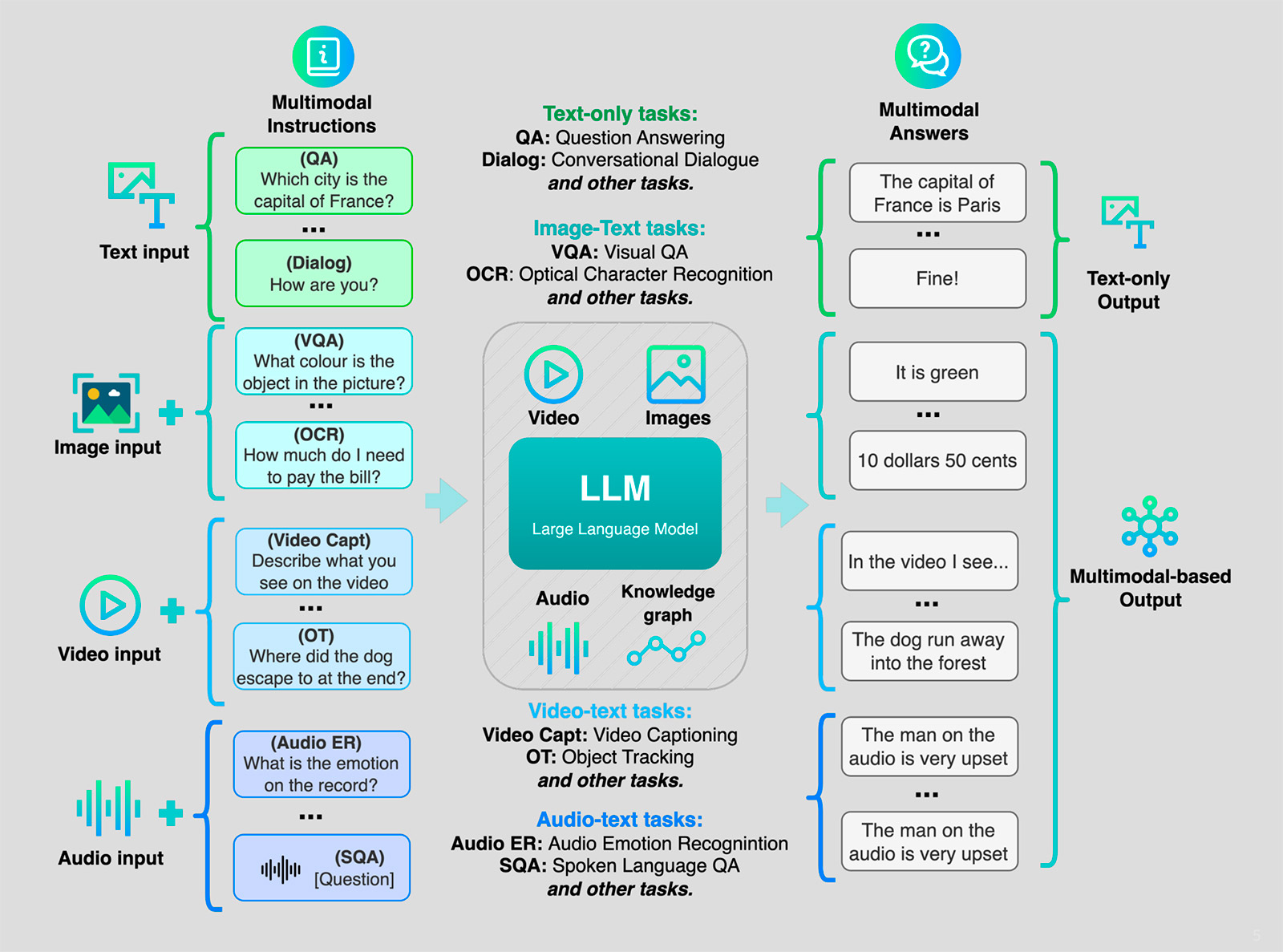
Справа — задачи не только в одном домене или в одной модальности, но ещё и на пересечении этих модальностей. Появляются ответы на вопросы по картинкам, можно добавлять подписи к картинкам, строить диалог с пользователем на основе как языковой информации, так и дополнительной, визуальной или другой.
Изменение парадигмы в AI
Сейчас мы приходим к понятию фундаментальной модели, которое лежит в основе принципа мультимодальности сильного искусственного интеллекта.
Вместо создания отдельных типизированных моделей под конкретные задачи мы пытаемся построить модель, которая может решать сразу много задач одновременно и будет вычислительно эффективно обучаться.
Также мы сможем научить модель работать с разными типами данных. Это ведёт к попытке решить несколько задач для ИИ с помощью унитарного решения.
Мультимодальную архитектуру можно организовать тремя способами.
Tool-augmented LLM — самое простое решение, работа LLM в режиме оркестратора. Есть сильная языковая модель, которую на инструктивных сетах мы обучаем вызывать внешние системы. Есть много алгоритмов, которые умеют работать с картинками — например, распознавать объекты, детектировать, сегментировать, давать семантику на выходе.
На основе выходов этих моделей мы создаём специальный контекст для языковой модели. Она умеет делать такие операции с картинками, на самом деле не зная, что такое картинка. Модель понимает, как можно работать с картинкой из выдачи внешних систем.
End-to-end multimodal LLM — обучение языковой модели сразу на нескольких типах данных. Берём архитектуру «трансформер», начинаем подавать перемешанные данные, которые закодированы текстовым и картиночным энкодерами, но это только в примере для двух модальностей. Далее начинаем её учить в смешанном стиле. Вычислительно это очень трудоёмкая задача. Также непонятно, как добавлять новую модальность.
Modality bridging with pretrained models
Считаем языковую модель мозгом нашей системы и пытаемся научить её понимать новый язык. Язык изображений или любой другой модальности для языковой модели должен быть просто новым языком. Если получится правильно адаптировать латентное пространство изображений к латентному пространству текстовых представлений, мы научим модель работать как минимум с двумя типами данных.
По такому же принципу можно думать о том, как в дальнейшем кодировать и добавлять новый тип данных.
Мультимодальность + LLM. OmniFusion
В 2023 году команда FusionBrain представила архитектуру OmniFusion. Это первая в России архитектура, которая позволяет работать одновременно и с картинками, и с текстом.
Ключевые особенности:
- В основе лежит архитектура GigaChat 7В.
- С помощью спецтокенов для начала и окончания картинки учим модели воспринимать изображение. Взяли идею из архитектуры FROMAGE и доработали, чтобы получить лучшие показатели метрик на бенчмарках.
- В качестве визуального энкодера использовались CLIP-VIT-bigG / CLIP-VIT-Large.
Детали реализации. В качестве адаптера мы выбрали однослойный энкодер трансформера для выравнивания картиночных эмбеддингов. Эта операция обычно называется alignment.
С точки зрения оптимизатора было две стадии. Первая — pretrain, на которой учился сам адаптер и спецтокены картиночных эмбеддингов. Вторая — supervised fine-tuning (SFT), на которой обучалась вся модель, и с низким learning rate её дорабатывали на разных инструктивных сетах.
Использовали спецтокен начала и конца картинки. Для обучения диалогам ввели два спецтокена: [BOT], то есть слова ассистента, и [USER] — реплика, которая в диалоговом сете имитирует ответ пользователя.
Как правило, на SFT использовались семплы из открытых датасетов: COCO (58,3%), Visual Genome (13,8%), GQA (11,5%), OCR-VQA (12,8%). Также была часть приватного сета, собранного вручную разработчиками.
Процесс обучения включал две эпохи: эпоха на pretrain и эпоха на SFT. Обе были достаточно быстрыми благодаря адаптерам 2x Tesla A100.
Обучение каждой из архитектур заняло около двух суток. Как только параметры определены, сама процедура занимает около четырёх суток.
Benchmark-датасеты
Принято измерять мультимодальные модели на 9–10 датасетах, которые представляют собой диалоговые, image-captioning или VQA-типы. В датасетах представлены картинки с вопросами и ответами по этим изображениям. При этом картинки, вопросы и ответы собраны разными способами. Например, в подготовке viz-wiz датасетов участвуют люди с проблемами зрения для того, чтобы задать правильные вопросы о картинке и понять, что на ней изображено.
Остальные бенчмарки также содержат в себе картинки. Например, OCR benchmark позволяет оценивать, насколько хорошо модель умеет распознавать символы.
Полученные результаты
Для оценки результатов моделей используются классические метрики типа accuracy. Представление выглядит как круговая диаграмма. На её внешней окружности написано название каждого из бенчмарков. Чем ближе к внешней окружности точка, тем выше качество решения.
Качество решений OmniFusion для большинства задач сопоставимо с LLaVa, хотя OmniFusion имеет в два раза меньше параметров.
При этом в датасетах встречаются более технические вопросы по специфическим областям.
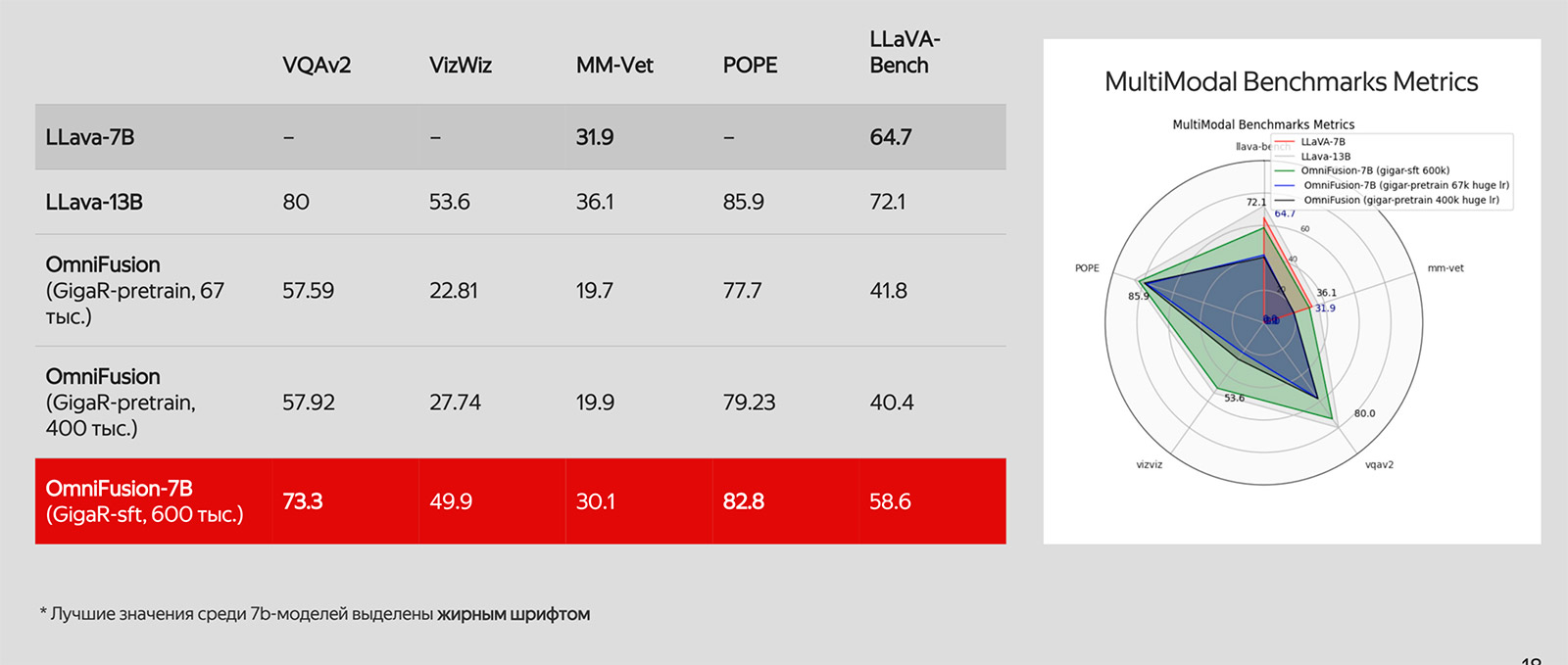
Команда сравнивала OmniFusion с другими семимиллиардными версиями и посмотрела, как качество вывода на бенчмарках меняется в зависимости от выбора базовой языковой модели. Брали базовый pretrain и два чекпойнта с SFT языковой модели.
При хорошем SFT-tune языковой модели качество ответов мультимодальной модели тоже сильно увеличивается. Знания, заложенные в языковой модели, важны для построения правильных ассоциаций, когда мы добавляем в неё язык визуальных образов.
Visual Dialog
Для оценки диалоговых способностей модели в мультимодальном формате мы сделали собственный бенчмарк Visual Dialog. Он включает в себя картинки, тексты и аудио. Но для этой задачи использовали только текстовые и текстово-картиночные диалоги.
Аудиоданные использовались на соревновании Strong Intelligence на AI Journey для оценки качества решений участников.

Если сравнивать OmniFusion с LLaVa по метрикам ранжирования, указанным на картинке, OmniFusion выигрывает на несколько процентов у тринадцатимиллиардной версии.
Также мы провели сравнение различных способов кодирования картинок.
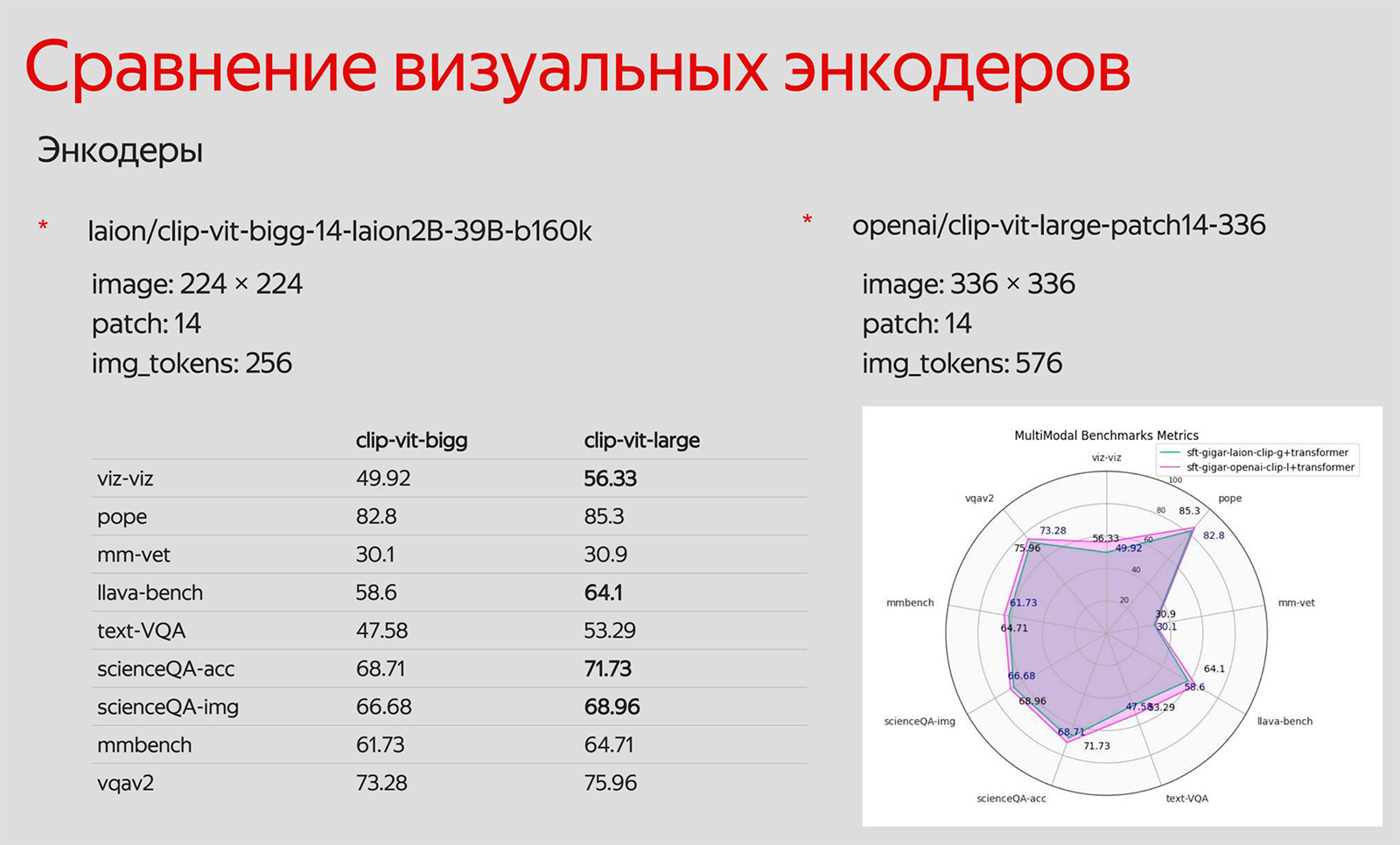
Модель с 576 токенами достаточно большая и вычислительно затратная, однако её показатели лучше, чем у модели с 256 токенами.
Команда выбирала, на каком из визуальных энкодеров остановиться. Есть два важных фактора. Первый: языковая модель, состояние её обучения (fine-tune), выбор чекпойнта в качестве базовой языковой модели. Второй: выбор энкодера. Чем больше в нём image-токенов, тем лучше и качественнее мы будем кодировать информацию.
Примеры диалогов
Модель научилась считать предметы, распознавать небольшие фрагменты текста, объекты архитектуры или достопримечательности, блюда, цифры и даже умеет определять место по скрину карты местности.

Интересный момент — картинки в центре, на которых издалека виден портрет человека, а вблизи — отдельные предметы.
Модель умеет смотреть на эти картинки абстрактно и даже определила личности людей на них. На вопросы, из чего состоят волосы и глаза человека, она отвечает — яблоки и листья.
Также попробовали реалистичные изображения из обычной жизни. Дали модели посмотреть картинку перелома ноги и задали вопрос, что не так на снимке. Модель поняла, что это нога, и верно определила трещину в кости.
Мультиагентность + LLM
Языковые модели, например ассистенты на основе базового ChatGPT, показали себя хорошими коммуникаторами. Задачи Тьюринга для них уже не выглядят суперсложными, потому что порой нельзя отличить модель от живого человека.
В 2023 году стало активно набирать популярность направление мультиагентных языковых моделей. Мы можем научить языковые модели или поместить их на интерактивную площадку, где они будут общаться.
При этом в ходе общения — своего рода мозгового штурма — можно дать им задачу и заставить решать её внутри себя. Можно взять несколько языковых моделей или даже одну и заставить её общаться саму с собой, просто придав ей какую-то роль.
В данном случае языковая модель становится AI-агентом, который умеет оперировать разными входами и типами данных, на основе этого выполняет действие по отношению к среде. При этом внутри себя оперирует планированием, декомпозицией задачи, работает с подобием памяти. Такая модель представляет собой аппроксимацию мозга.
С помощью разнообразных инструментов языковая модель умеет оперировать или взаимодействовать с миром.
Основные компоненты LLM-агента

Компоненты агента:
- Профиль модели — заложенные в ней знания.
- Память — способ хранения данных о взаимодействии с другими агентами или запоминания краткого контекста.
- Планирование — всё, что связано с декомпозицией задач и с задачами серии self-reflection. При этом модели учатся оценивать свои и чужие ответы, у них возникает возможность критичного взгляда на различные ответы.
Как же заставить модель критиковать и рассуждать логически? Сейчас есть два основных механизма, которым учат языковые модели: Chain of Thought и Tree of Thought. Это способы воздействия на языковые модели для их обучения декомпозировать задачи и логически строить выводы от точки к точке, то есть чтобы каждая задача имела возможность быть решённой разными способами.
LLM-агенты и роли доменно-специфичных задач
Например, есть задача по математике. Зададим модели роль эксперта по математике и попросим решить задачу. Поставим вопрос не просто в general-домене, а попытаемся сместить модель в её внутреннем векторном пространстве.
Команда FusionBrain исследовала внутренние способности и свойства модели и пришла к выводу, что внутри есть конусообразные представления в векторном пространстве, которые позволяют качать модель в разные стороны. Из-за этого у неё возникают разные свойства, которые приняли считать связанными с определённой ролью.
На самом деле у неё есть эти знания, просто мы поместили вектор ответов в нужное подпространство её признакового описания. Наша задача — посмотреть, как архитектура и семейство выбранных языковых моделей может влиять на ответы модели.

Взяли две языковые модели, Mistral-7b и Qwen-7b-chat, и стали задавать им промпты, экспертные для разных специфических задач из профессиональных областей, тестов из колледжей.
Бирюзовый многоугольник в центре — базовое состояние модели, когда мы даём ей задачи и она начинает на них отвечать. Разными цветами представлены варианты задания специальных промптов. Можно задавать промпт, что модель — просто эксперт или что она — эксперт в конкретной области в зависимости от бенчмарка. Также мы можем задавать ей системный промпт не под задачу, а в целом на способности работы модели.
При выборе любого из специальных вариантов можно видеть, что модель начинает лучше отвечать на экспертные различные задачи. Синяя линия на графике — системный экспертный промпт. На Mistral-7b он показывает себя лучшим образом, модель начинает в своём пространстве ответов искать ответы специфически под конкретный домен.
Мы решили посмотреть, как модель будет решать задачу, если её одну запромптить в разные роли.
Эксперимент: дискуссия с использованием ролей
Было два эксперимента. Первый — одна дискуссия и несколько ролей, второй — несколько дискуссий и несколько ролей. Мы взяли модель LLaMA-2-7b-chat и заставили её ответить на вопрос, в чём смысл жизни и что такое Вселенная. Модель ответила абстрактно.
Вопрос попробовали решить с помощью теолога, биолога и философа. В качестве системного описания дали ей не только описание ролей, но и порядок ведения дискуссии.
Игра длилась три раунда, затем формировали ответ. На каждом из раундов модель отвечала в соответствии с предыдущими ответами — как своими, так и других участников дискуссии. Получался увеличивающийся постоянный контекст, на который модель опиралась в поиске ответа.

Здесь показано несколько вариантов дискуссии. После трёх раундов появился ответ с тремя экспертными оценками.
В ходе диалоговой игры получилась коммуникация, которая привела к более логичному ответу, чем первоначальный. Получили ответ с точки зрения экспертизы в конкретной области.