История появления генеративных моделей
Основные этапы развития генеративных моделей:
- 2014 год: появление GAN-сетей — толчок в развитии генеративных (особенно визуальных) моделей
- 2016 год: по мнению спикера, первое успешное решение задачи генерации изображений по тексту с помощью GAN, S. Reed et al. (ICML 2016, NeurIPS 2016)
- С 2017 года практически ни одна ML-конференция уровня A/A* не проходит без публикаций на тему синтеза изображений по текстовым описаниям
- 2018 год: одна из первых работ о генерации видео по текстовым описаниям, Li Y et al
С 2014 года разрабатывали различные генеративные архитектуры: GAN, вариационные автокодировщики, flow-based модели и авторегрессионные модели.
В конце 2021 года учёные отдали предпочтение диффузионным моделям.
Плюсы диффузионных моделей:
- Нет состязательного обучения, которое трудно устроить у GAN.
- Нет mode collapse, когда модель начинает воспроизводить только один класс или вырождаться.
- Качество генерации лучше.
Минус диффузионных моделей — генерация требует больше времени, потому что это пошаговый процесс. Последние разработки позволяют сократить количество этапов до 1–2, нивелируя данный недостаток и приближаясь к real-time генерации изображений.
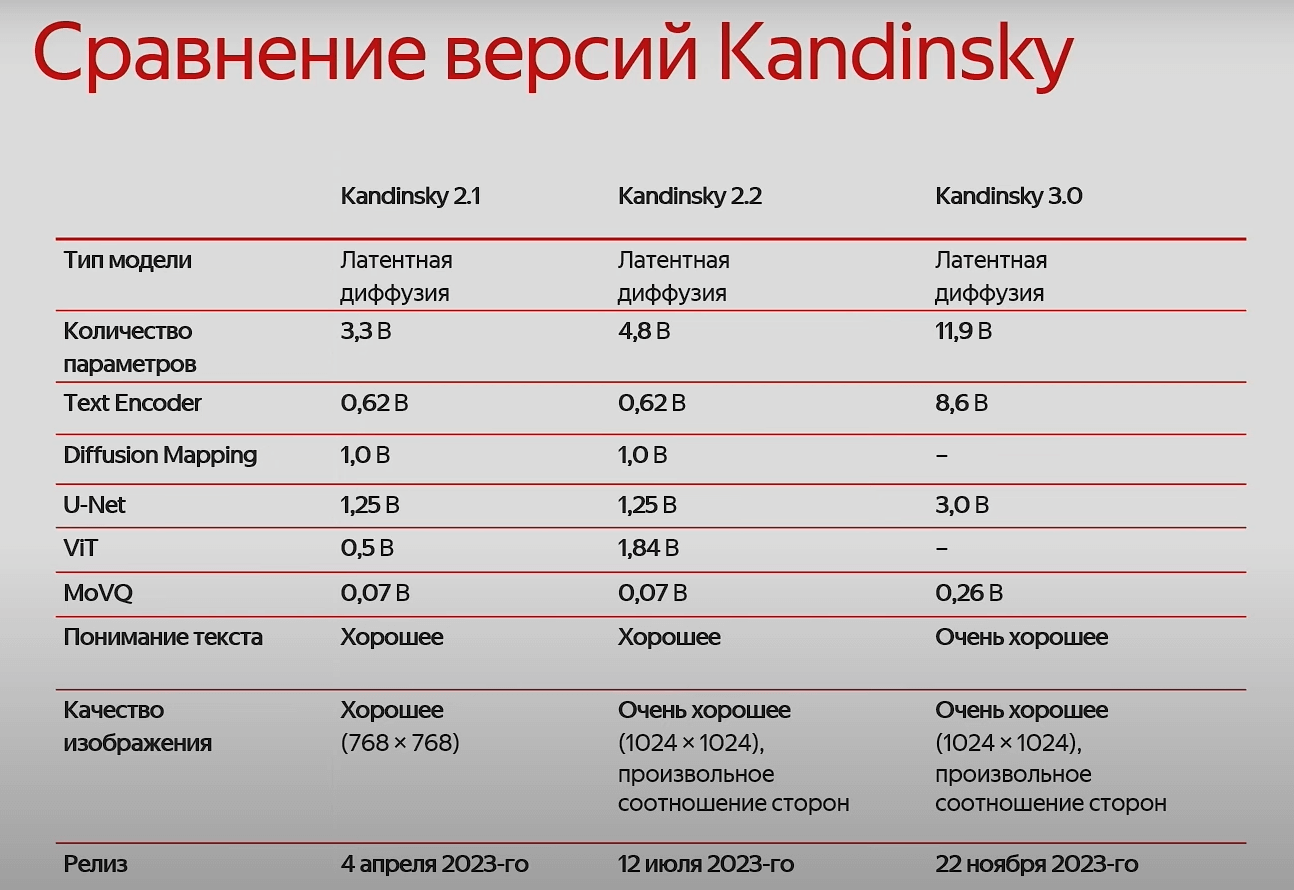
Модели Сбера. Сбер разрабатывает модели генерации изображений с 2021 года. За это время вышло семь моделей, а подход изменился с авторегрессионного на диффузионный.

В конце 2023 года разработчики представили модели Kandinsky 3.0 и Kandinsky Video.
Диффузионная генерация изображений по тексту
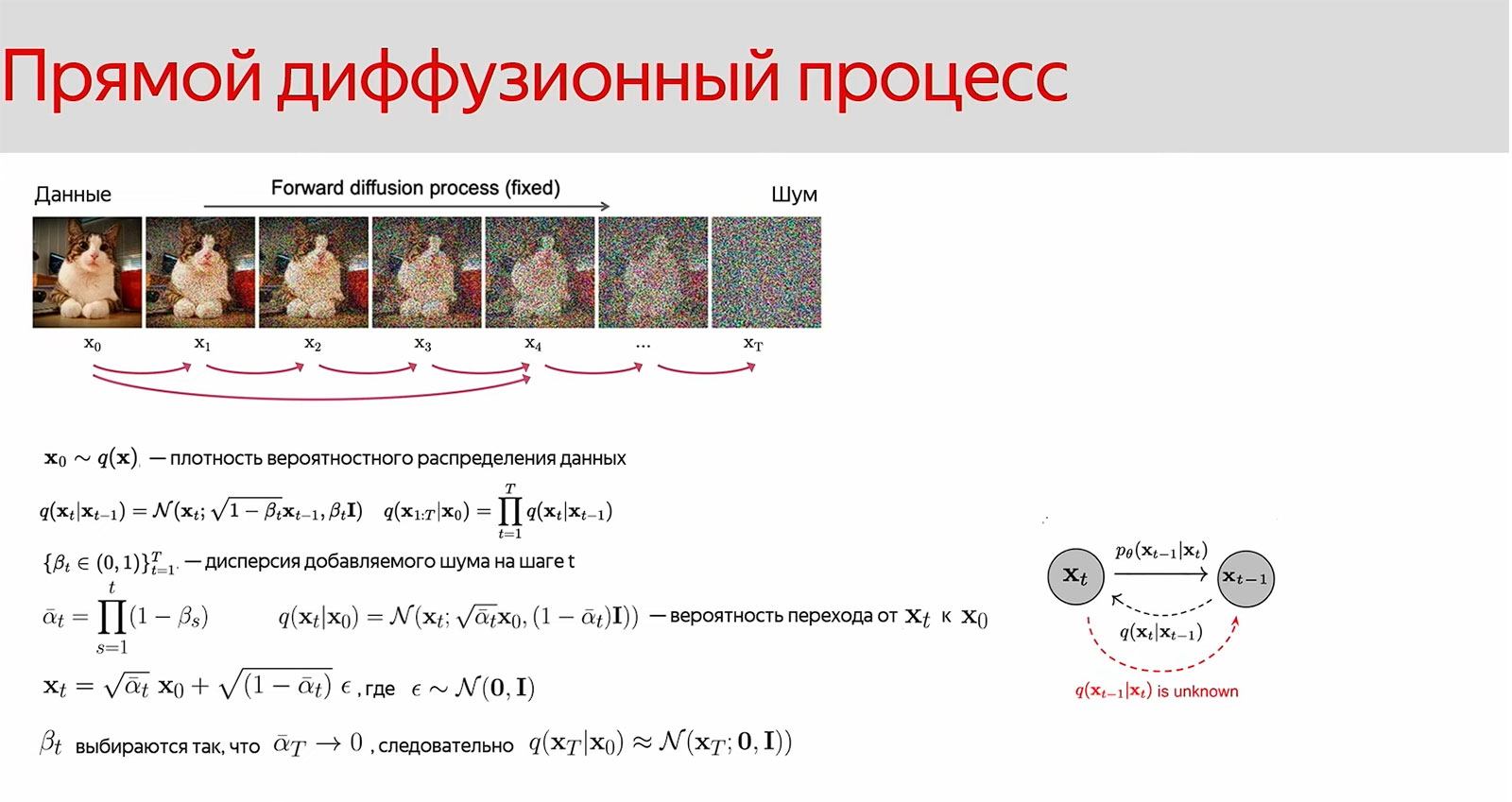
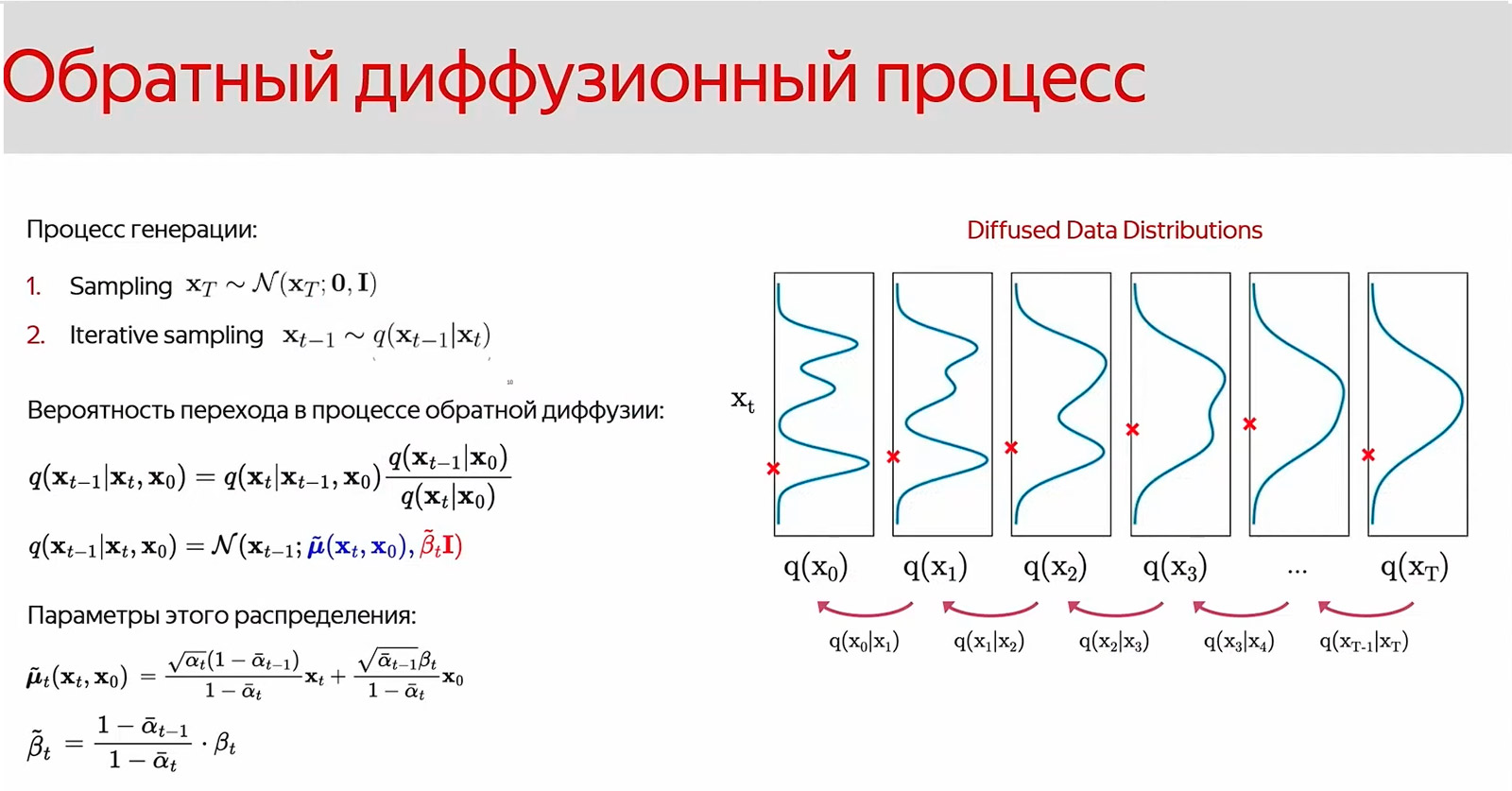
Диффузионный процесс состоит из прямого (генерация изображения) и обратного (устранение шума). Нейросеть использует текстовое описание и из шума пошагово получает изображение.
Математическое описание генерации картинки

Базовая архитектура U-Net. Чтобы предсказывать среднее значение выхода нейронной сети pΘ, используют архитектуру U-Net, у которой вход и выход имеют одну размерность. Это как раз то, что нам нужно, потому что в ходе диффузионной генерации изображения мы прогоняем одну и ту же картинку, шаг за шагом убирая шум.
В Kandinsky 3.0 используется прокачанная версия U-Net, у которой расположение блоков отличается от того, которое использовалось для первой версии. Если мы хотим сгенерировать картинку по тексту, нужно модифицировать слои U-Net — через cross-attention добавить эмбеддинг текста.
Как работает генерация. Общая схема генерации картинок в Stable Diffusion, DALL-E 2, DALL-E 3, Шедевруме и Kandinsky одинаковая. Текст кодируется текстовым энкодером. Затем на основе закодированного текста и шумной картинки U-Net пошагово денойзит шум в направлении вектора в семантическом смысле. В итоге получается картинка.
При этом модели различаются в деталях. Например, у Kandinsky и DALL-E 2 есть дополнительный блок, который преобразует текстовые эмбеддинги в визуальные и облегчает декодирование для U-Net.
Kandinsky 3.0
Kandinsky 3.0 имеет оптимизированную архитектуру U-Net.
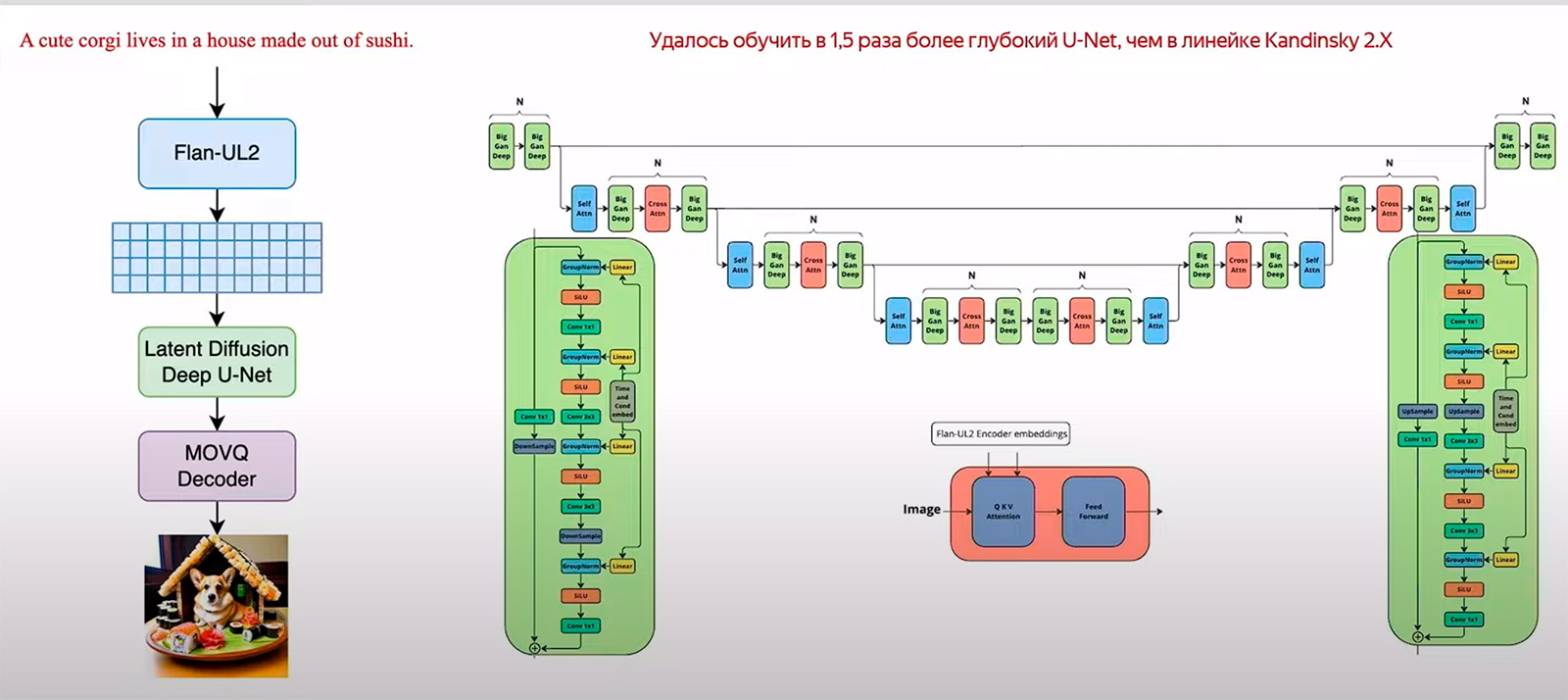
В версии 3.0 убрали Image Prior — дополнительную модель, которая переводит текстовый эмбеддинг в визуальный, потому что с ним трудно работать при обучении ControlNet и inpainting.
Использованные данные. Модель учили в несколько этапов и повышали разрешение изображений для обучения с 256 до 1024 пикселей.
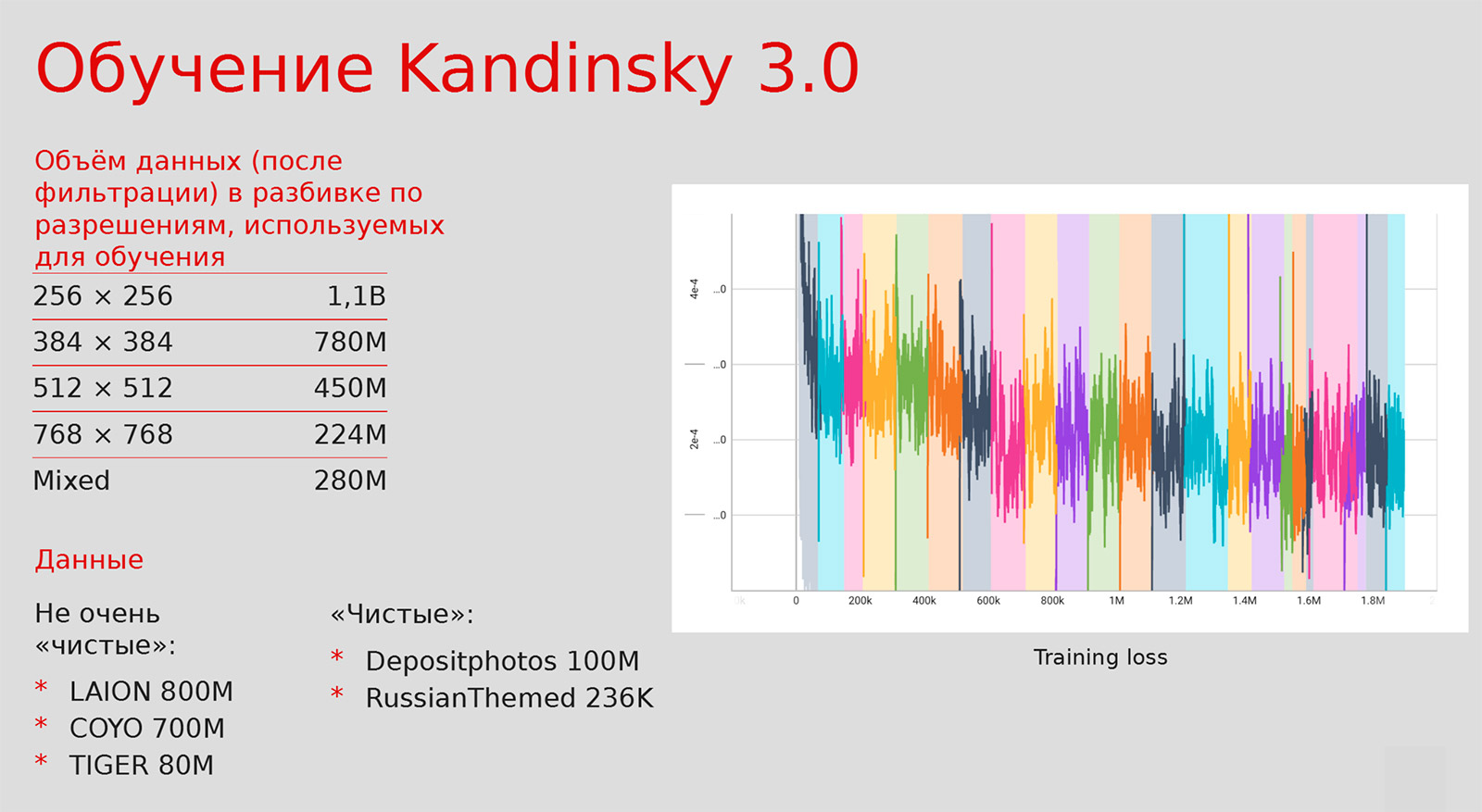
Автоэнкодер MoVQ. Важно учитывать, что при генерации картинки происходит латентная диффузия. То есть модель денойзит изображение не в пространстве пикселей, а в некоем латентном пространстве, которое получается с помощью энкодинга моделью MoVQ. На самом деле это MoVQGAN, который можно представить как автоэнкодер: есть энкодер и декодер, кодируем картинку в латентном пространстве, денойзим диффузией и восстанавливаем.
MoVQ отвечает за часть декодинга картинки, поэтому важно было прокачать этот автоинкодер в плане восстановления изображения. По состоянию на август 2023 года он был на сотом месте в рейтинге решений для этой задачи.
Side-by-side сравнение Kandinsky 2.2 и Kandinsky 3.0
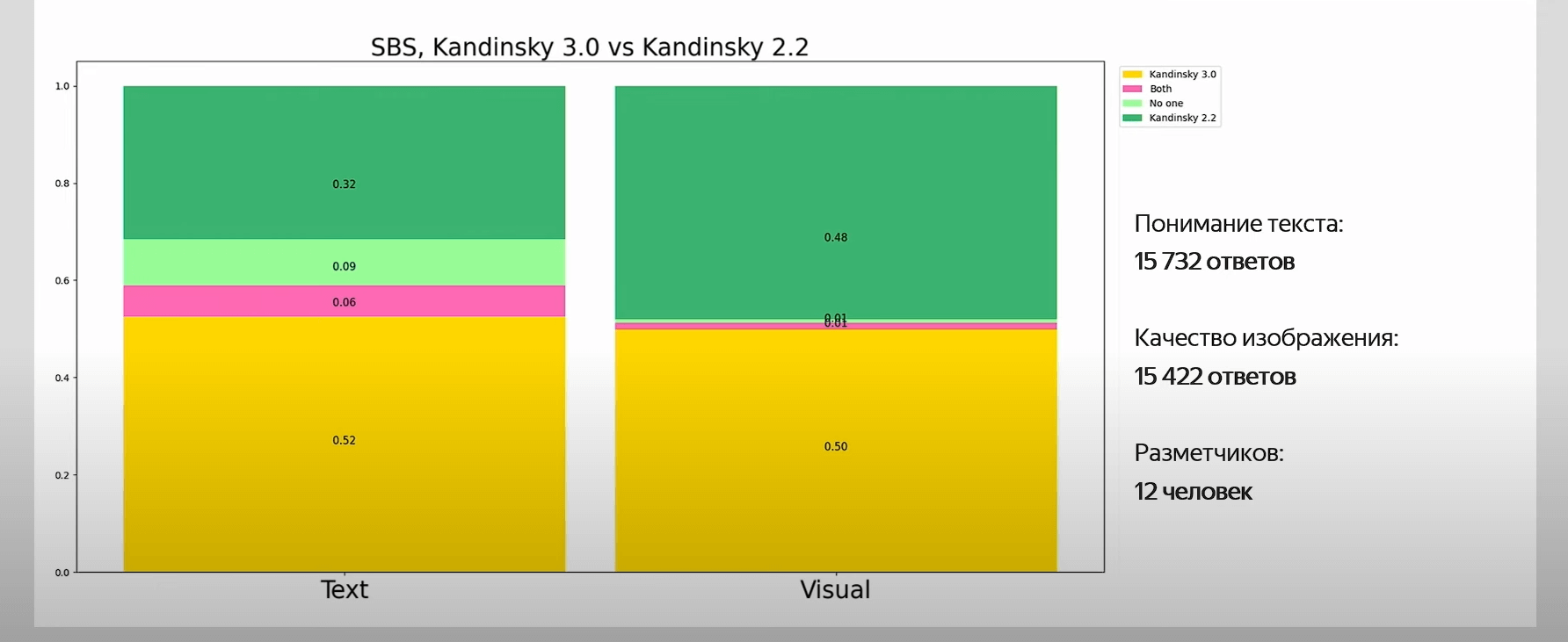
Для сравнения Kandinsky 2.2 и Kandinsky 3.0 создали бота и опрашивали двенадцать человек. В первом случае показывали респондентам текстовое описание и две картинки, одна из которых сгенерирована на основании текста моделью Kandinsky 2.2, а вторая — Kandinsky 3.0. Спрашивали, какая картинка больше подходит по смыслу к исходному описанию. Версия 3.0 превзошла версию 2.2 — 0,53 против 0,32.
Во втором случае людям показывали две картинки и спрашивали, какая из них им нравится больше. По итогам версия 3.0 обошла версию 2.2 — 0,50 против 0,48.
Итоги. Для сравнения версий построили локальный бенчмарк из 21 домена, в каждом из которых было 100 промптов. Kandinsky 3.0 значительно превосходит Kandinsky 2.2 по пониманию текста и по качеству изображения.
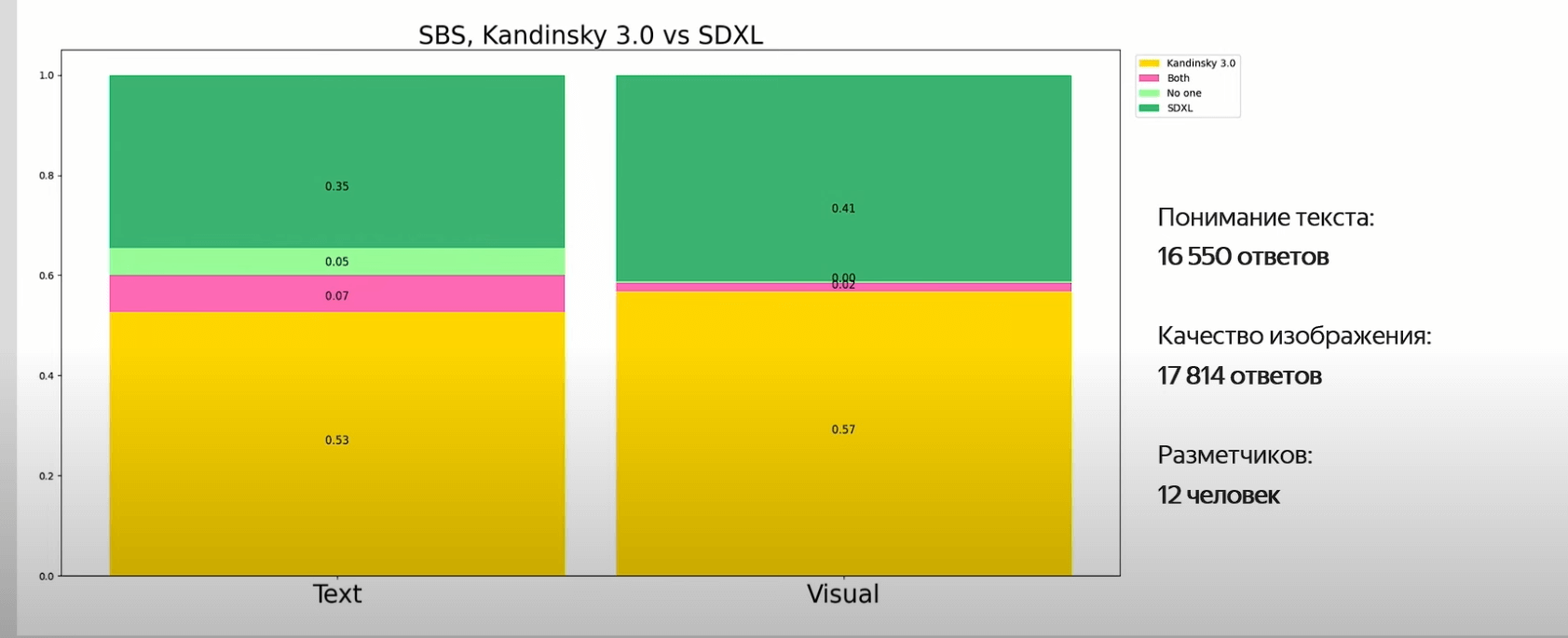
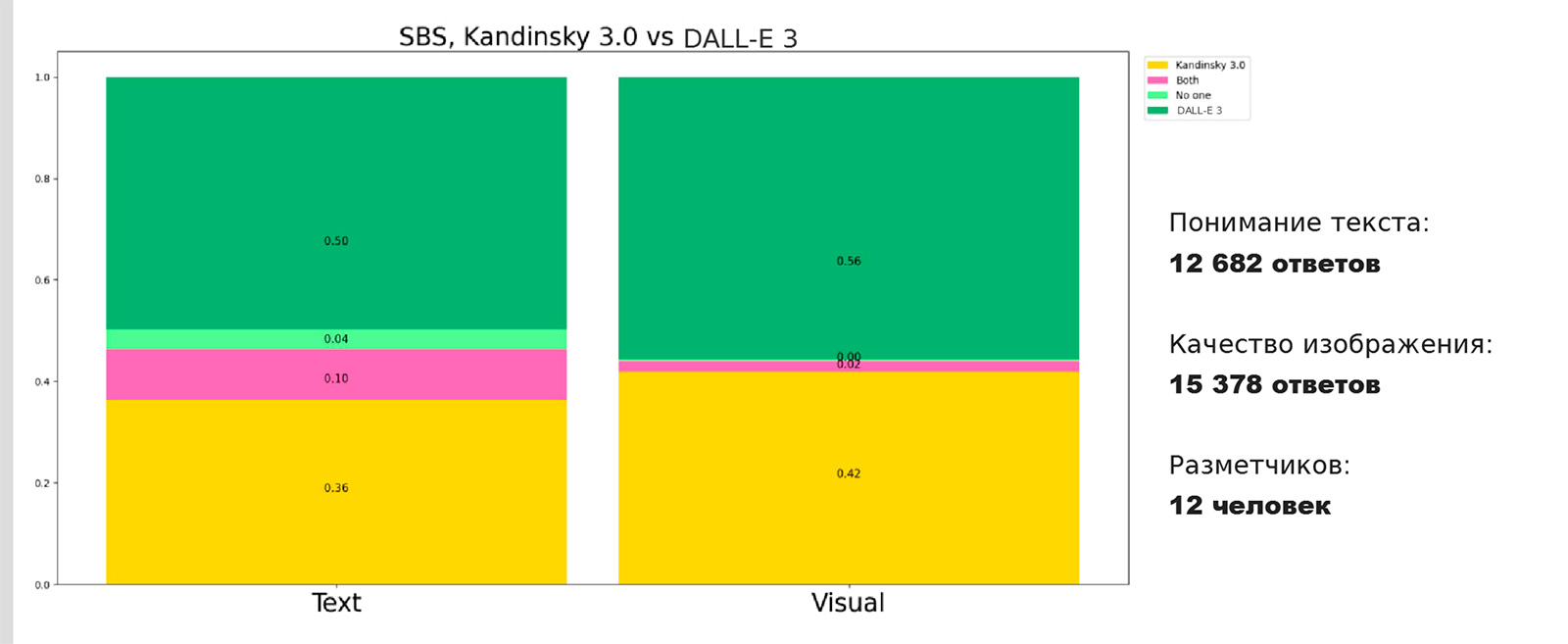
Side-by-side сравнение Kandinsky 3.0 с SDXL
Kandinsky Inpainting. Модель, которая стартует с базового претрейна Kandinsky 3.0 и учится «дополнять» изображения.
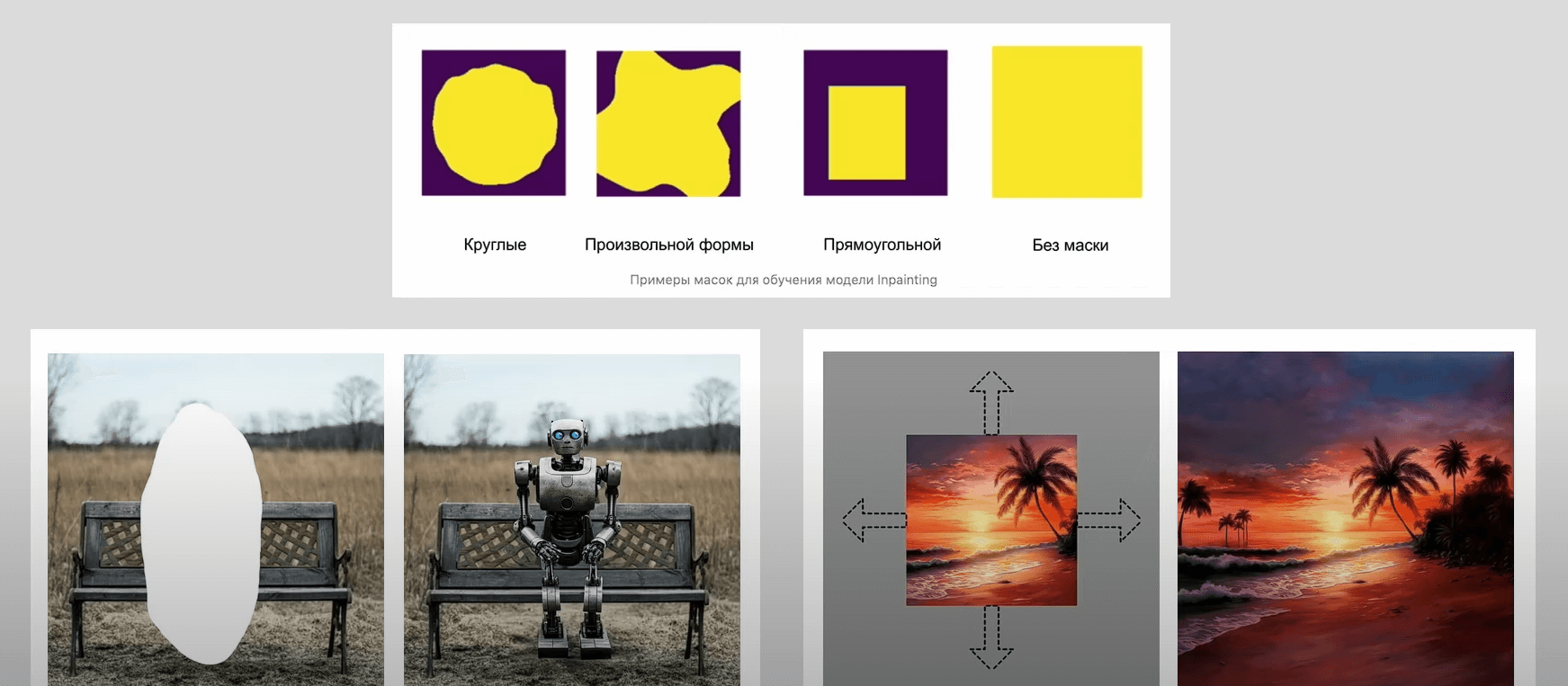
Протестировать Kandinsky 3.0 можно в боте и по ссылке.
Диффузионная генерация видео по тексту
Почти все генераторы видео строятся на моделях text2image. Существует много видов видео, поэтому сначала важно понять, что именно мы хотим получить.

Генерацию видео можно разделить на две части: анимационные видеоролики и полноценное видео. В анимационном видеоролике объект не двигается, анимация моделирует пролёт камеры вокруг статичного объекта. Например, в случае zoom in / zoom out анимации есть исходное изображение, и мы дорисовываем окружение с помощью inpainting или outpainting. Затем приближаем или отдаляем изображение.
В полноценном видео все объекты двигаются. Используется отдельная модель, которая часто стартует с весов text2image модели, но затем учится.
Deforum
Генерируем по тексту изображение любой моделью, например диффузионной. Потом реконструируем псевдо-3D-сцену над этим изображением. На вход есть эффект, например zoom in. Моделируем в 3D-пространстве эффект приближения — делаем детерминированное преобразование в 3D и берём проекцию. После этого пошагово сдвигаемся в изображении и каждый раз перерисовываем его. В итоге получаем анимацию.
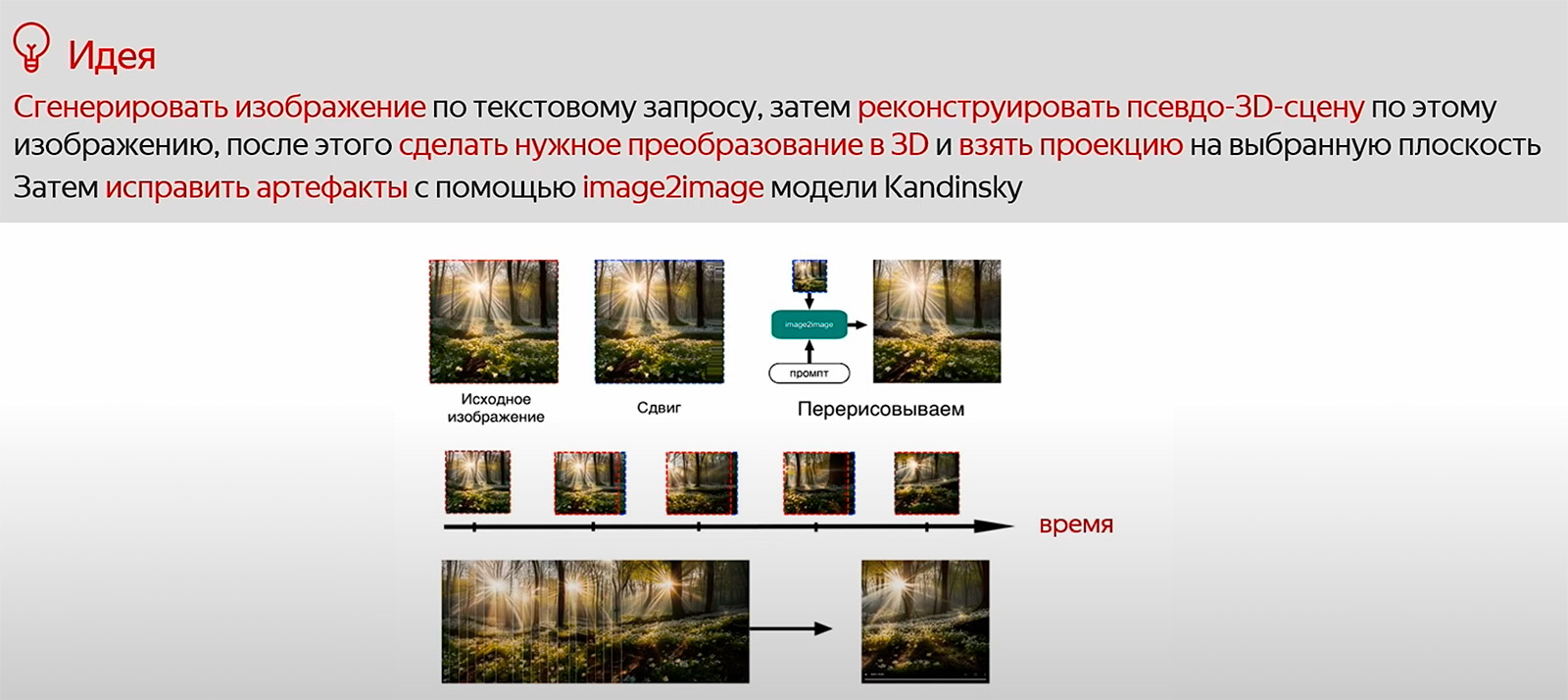
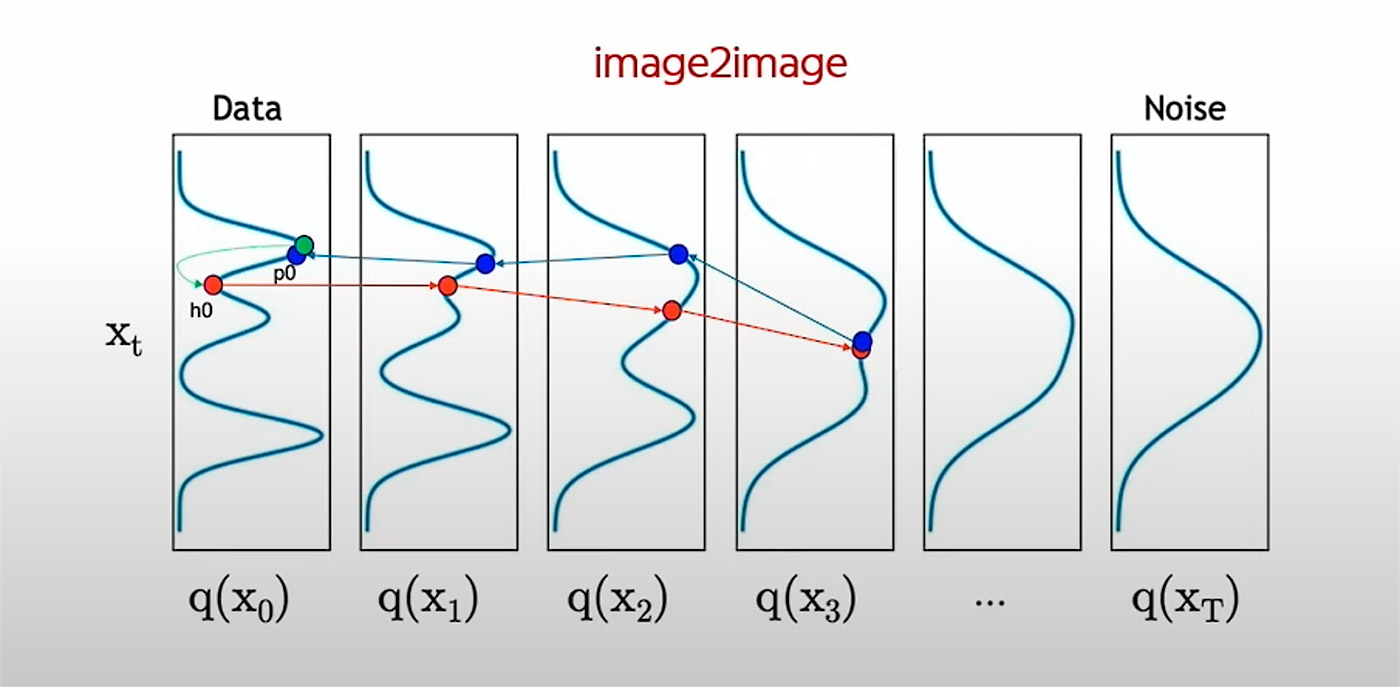
На рисунке ниже изображён image2image режим работы диффузионных моделей. Его используют, поскольку у псевдо-3D-преобразований качество картинки не очень хорошее. Вы берёте изображение и используете предобученную модель. Стартуете с красной точки h0 с маленькой вероятностью, то есть изображение нереалистичное. Вы зашумляете его примерно на 20 шагов, а потом расшумляете обратно той же моделью. Красная точка становится синей, которая более вероятна с точки зрения данных и более реалистична для человека. Таким образом можно исправлять артефакты.
Реконструкция псевдо-3D-сцены. Для реконструкции сцены строим облако точек с помощью модели MiDaS, затем вычисляем облака точек над этой картой глубины.

Kandinsky Deforum (Kandinsky Animation) — базовая модель Kandinsky 3.0 или Kandinsky 2.2, которая работает без предобучений.

Генерация полноценных видео
Генерация полноценных видео требует обучения отдельной модели. Возьмём пример двух моделей. В этом случае модель генерации создаёт опорные кадры, а модель интерполяции делает видео гладким, то есть реалистичным.
Архитектура моделей
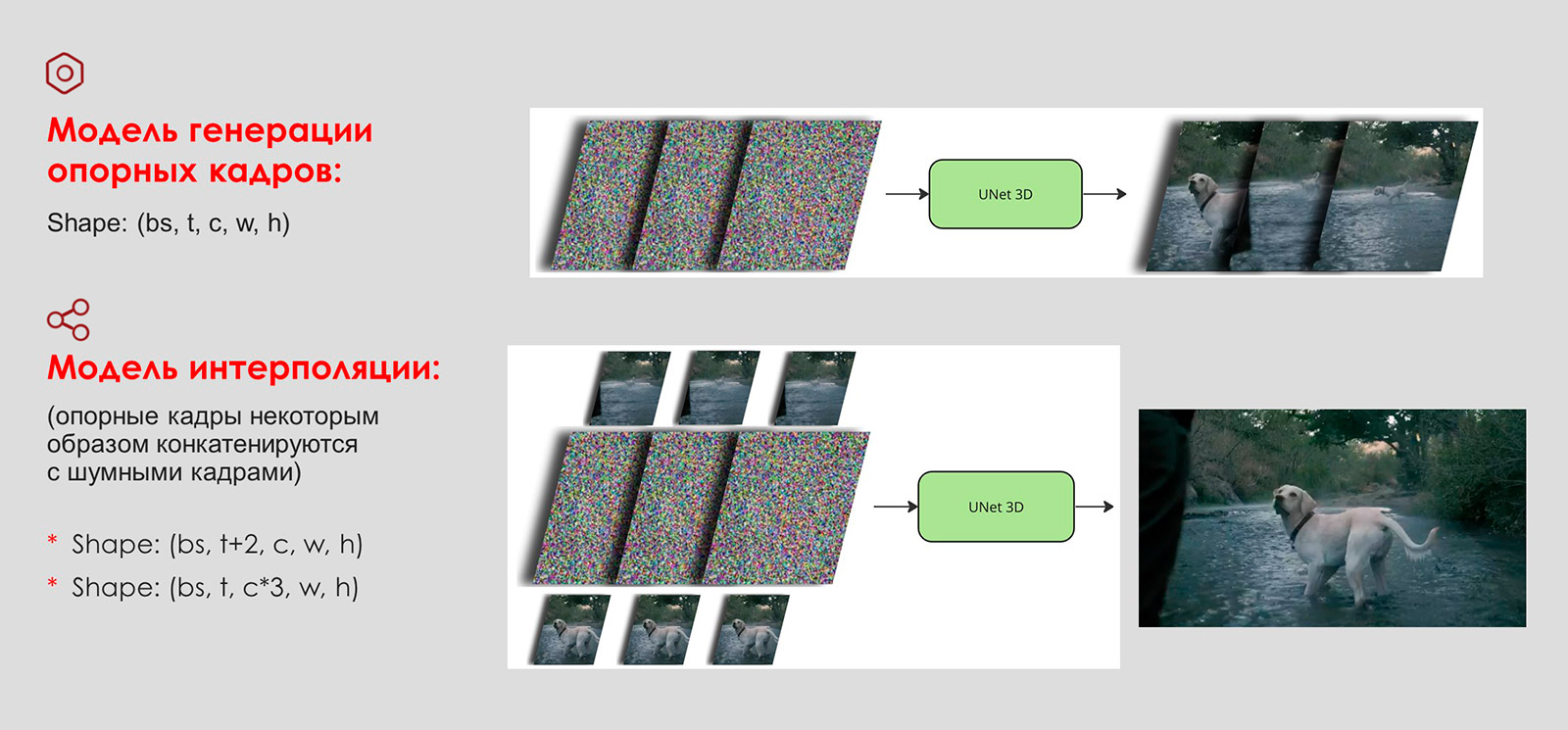
Это диффузионная модель, которая денойзит сразу пачку кадров как единый тензор. В итоге получается набор опорных кадров, которые кажутся динамикой.
Потом вы можете взять два базовых кадра и предсказать между ними десять интерполяционных кадров. Для этого даёте десять кадров между двумя опорными и денойзите их моделью.
Для более сложной задачи генерации базовых кадров нужна модель с бóльшим числом параметров. Маленькая и ёмкая модель интерполяции нужна для ускорения генерации видео.
Принцип работы. Из U-Net 2D делаем U-Net 3D, добавляя темпоральные слои. Они связывают кадры в пространстве, чтобы исследовать зависимость между ними и учить их.
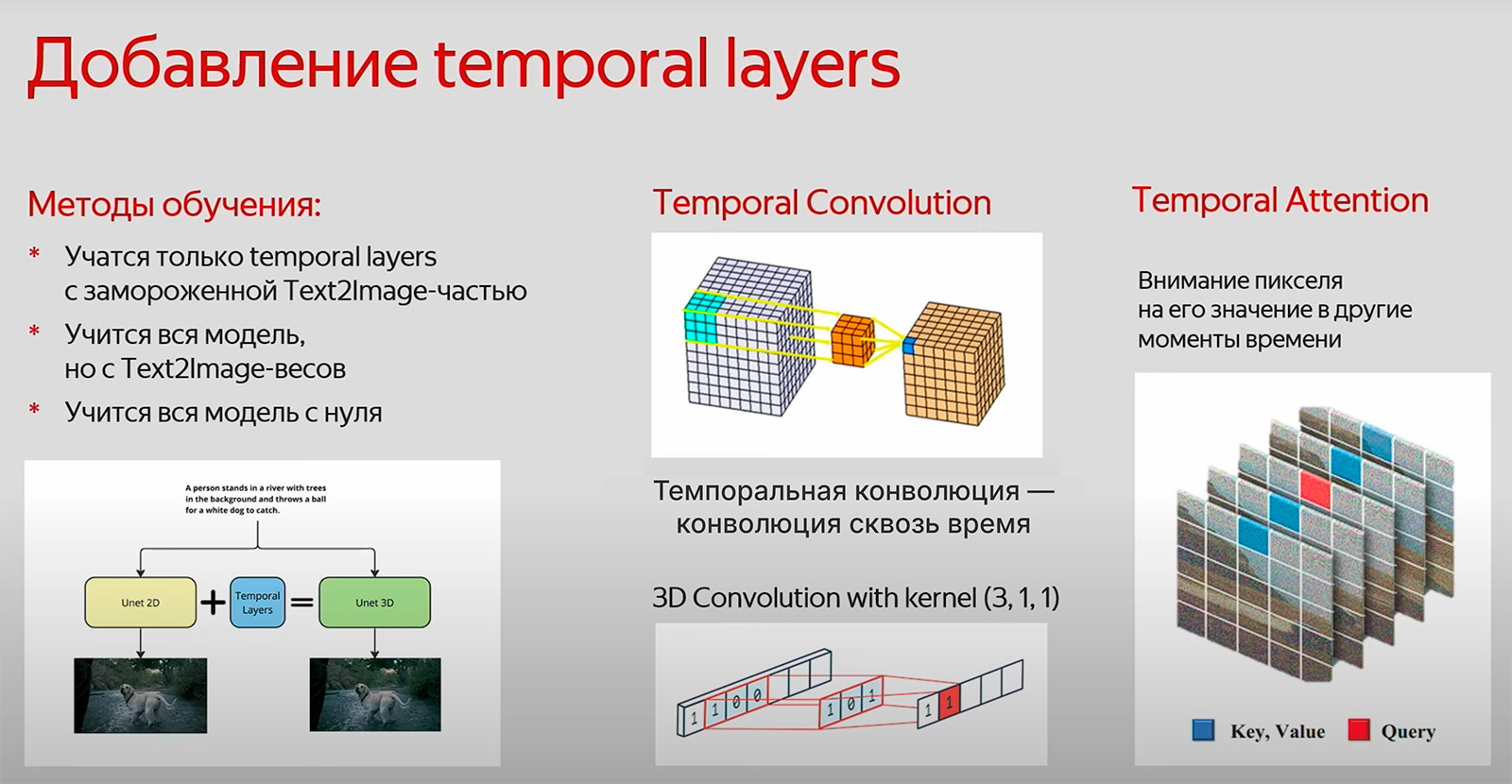
Можно обучать:
- Только темпоральные слои, замораживая text2image. Так обучается Kandinsky Video.
- Всю модель, но с text2image весов. Весь U-Net 3D.
- Модель с нуля.
Основные проблемы обучения text2video с нуля:
- Мало качественных данных.
- Данные однообразные.
Обучение text2video путём встраивания темпоральных слоёв в text2image:
- При дообучении только встроенных слоёв деградирует качество картинки.
- При дообучении всей модели деградирует понимание текста и знание разных сущностей, потому что мы обучаем модель на некачественных данных.
Итог. Обучение с нуля позволяет получить красивые генерации, но в очень узком домене. Поэтому в Sber AI выбрали fine tuning модели с использованием text2image-модели — это значительно ускоряет процесс.
Kandinsky Video
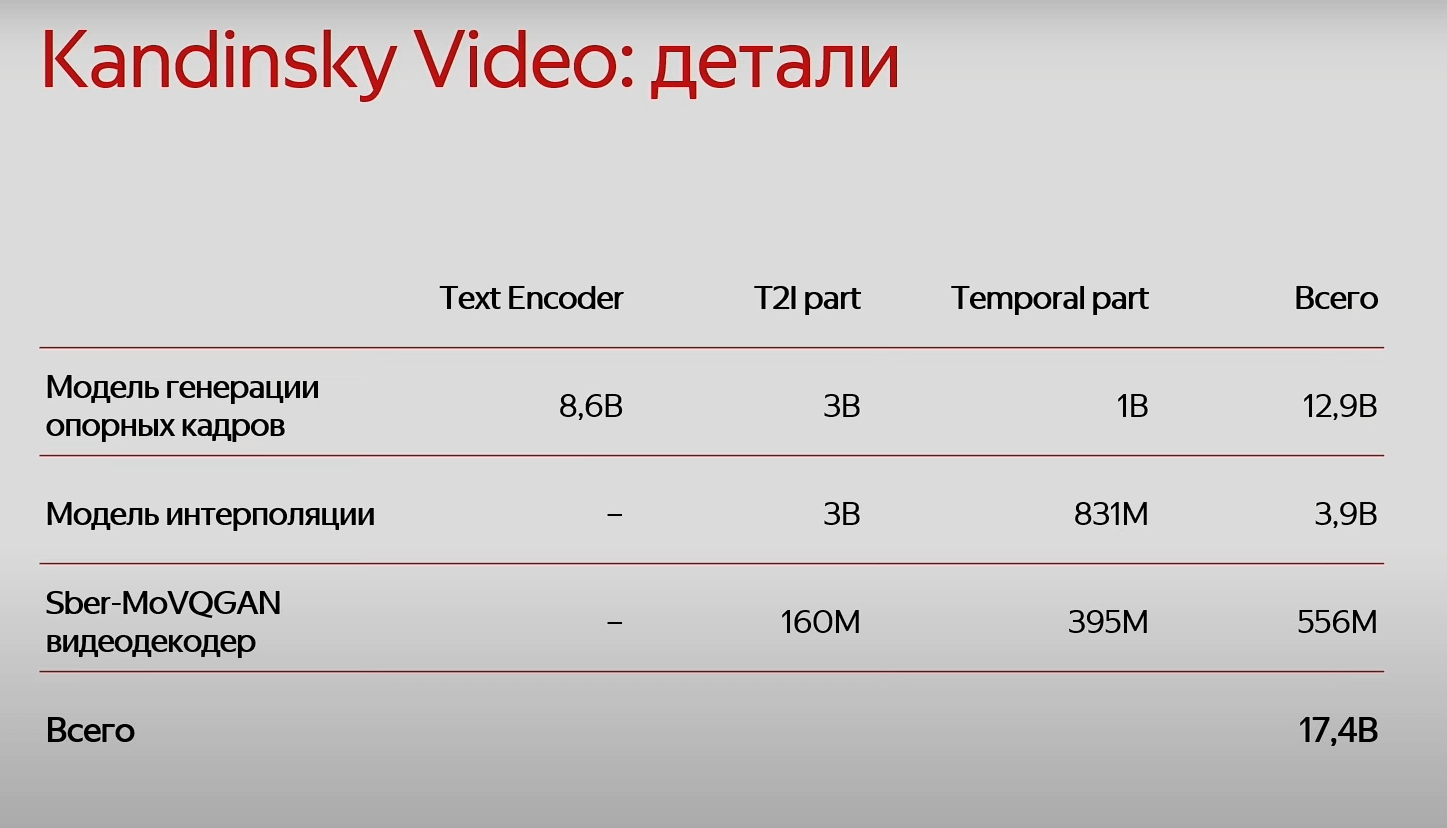
Архитектура. Kandinsky Video состоит из текстового энкодера, модели генерации опорных кадров и модели интерполяции, после которой получается полноценное видео. Модели учатся по отдельности.
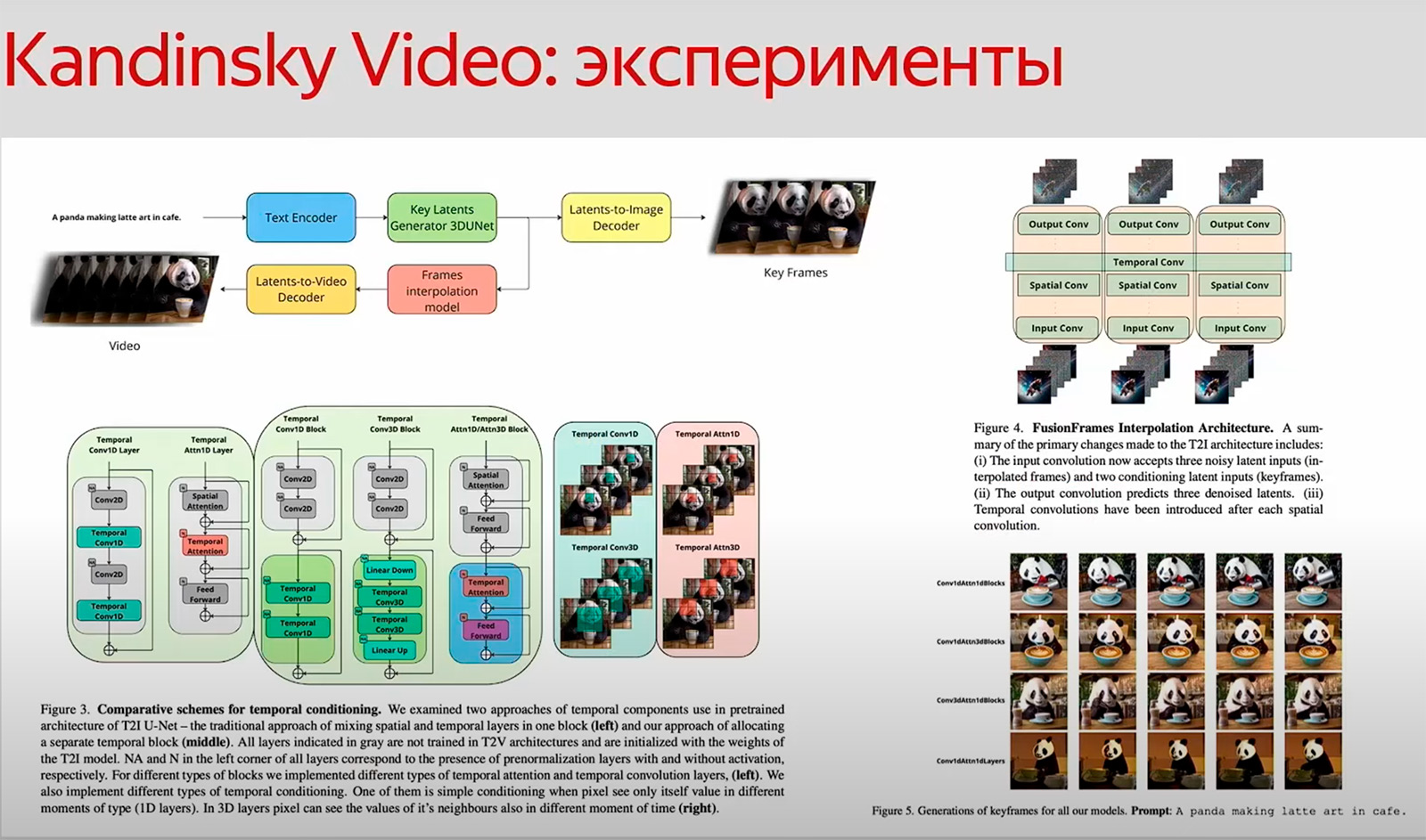
Классический подход — после слоя spatial ставить темпоральный и чередовать их. В ходе исследований команда разработчиков выяснила, что расположение темпоральных слоёв по блокам значительно улучшает качество финального видео.
Модель генерации опорных кадров и модель интерполяции строятся на базе Kandinsky 3.0.
Датасеты. Для обучения моделей генерации ключевых и интерполяционных кадров собрали набор из 220 тысяч пар «текст — видео».
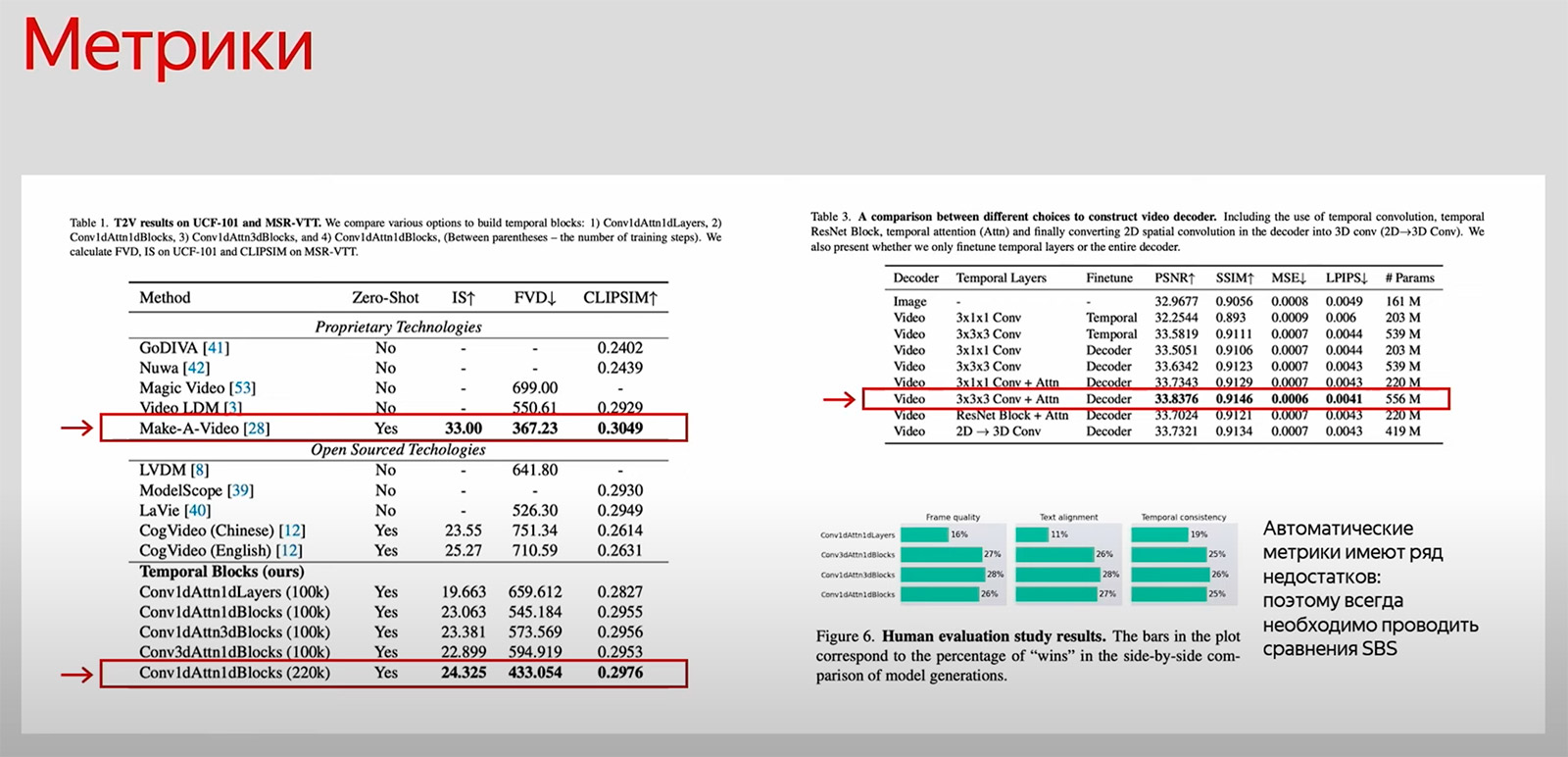
Разрабатываемую модель тестировали на двух бенчмарках: UCF-101 — набор видео, содержащих различные действия и полнотекстовые описания этих действий, и MSR-VTT — набор описаний видеороликов.
Разработчики также обучили специальный автоэнкодер MoVQ Video. Видео сжимается целиком, и учитываются связи между картинками. В итоге значительно прокачивается декодинг финального видео.
Итог. Модель Kandinsky Video по метрикам FVD (Freeshare Video Distance), IS (Inception Score) и CLIPSIM оказалась на втором месте после Stable Video Diffusion.
Также использовали human evaluation — спрашивали мнение разметчиков. Для финального обучения выбрали ту модель, которая больше всего им понравилась. По данным опроса, более высокую оценку получила архитектура, в которой темпоральные слои объединены в блоки. У разработчиков нет окончательного ответа на вопрос о том, какое решение оптимальное, но понятен общий вид архитектуры. Остаётся увеличивать число данных.
Протестировать Kandinsky Video можно по ссылке.
Заключение
Модели генерации изображений из текста уже активно используются в бизнесе для:
- Интеграции со стоковыми сервисами (Shutterstock × DALL-E 2)
- Разработки новых платформ для дизайнеров на основе моделей (Photoshop AI: Generative Fill и Generative Expand)
- Создания персонализированной и более эффективной рекламы (Сбер, Яндекс)
- Помощи в быту и в рабочих процессах (например, для иллюстрирования презентаций)
Модели генерации видео по тексту активно развиваются, однако пока не готовы к полноценному проду.
Эти модели не заменяют человека и специалиста, а являются их помощниками.