Формулируем задачу
При работе с рекомендательными системами контентных платформ важно учитывать следующие особенности:
- Контента становится всё больше. На это влияет в том числе развитие генеративных систем, благодаря которым люди могут быстрее воплощать свои идеи. Из-за этого порог входа для новых авторов становится всё ниже.
- Пользователи ограничены во времени, у них нет возможности тратить всё своё внимание на потребление новых материалов.
С одной стороны, мы видим огромное предложение, а с другой — ограниченный спрос. Сервису важно настроить рекомендательную систему так, чтобы среди всего многообразия статей и видео находить самое интересное. При этом нужно обращать внимание не только на пользовательские метрики, но и на удовлетворённость авторов.
Начинаем поддерживать авторов
Рекомендательная система в Дзене устроена так:
→ Есть база документов, она состоит из миллионов разных публикаций
→ На каждый запрос пользователя мы запускаем отбор из нескольких тысяч кандидатов
→ Дальше запускаем ранжирование и отдаём пользователю релевантные результаты

Качественные и количественные исследования показали, что для авторов, особенно начинающих, очень важно искать аудиторию — они сильно проигрывали на этапе скоринга, потому что о них пока мало информации.
Мы добавили стадию блендинга, чтобы квотировать долю материалов маленьких авторов, которые попадут в выдачу. Это дало результаты: +10% показов и +5% подписок.
Дальше решили ранжировать контент маленьких авторов отдельно. Применили к ним модель, которая предсказывает вероятность подписки на автора данного айтема. Подписки выросли на 10% при тех же 10% показов.
С точки зрения отдельного автора, которому мы решили помогать, статистика охватов выглядела так:

В тот момент, когда мы отключали пользователя от инструмента помощи, его охваты сильно падали. Для него это необъяснимая и, конечно, неприятная ситуация.
Появилась проблема: нужно было как-то разграничить маленьких и уже подросших авторов, чтобы точно понимать, когда их контент уже не нужно ранжировать отдельно. Именно поэтому мы сделали шаг назад и решили определить метрики, по которым будем оценивать эффективность работы нашей рекомендательной системы.
Определяем ключевые метрики
Мы хотим, чтобы у нас на платформе становилось больше активных создателей контента. Есть метрика, которая за это отвечает: WAU, или weekly active users. Растить WAU можно двумя способами: приводить новых пользователей и развивать существующих. Важно делать и то и другое, но мы обсудим развитие существующих.
Ожидаемое количество авторов, которые будут активны на платформе в течение, например, 90 дней, можно записать через формулу:

Математическое ожидание WAU — это сумма по всем авторам, индикатор того, что они будут активными. По линейности математическое ожидание заносим под знак суммирования, и получается сумма вероятности того, что пользователь останется в Дзене через 90 дней.
Вероятность возвращения на платформу можно оценить при помощи метрики Retention. Допустим, у нас была 1 000 авторов, а через 90 дней осталось 800 — значит, Retention нашей платформы в целом 0,8. Но нам интересно оценить Retention конкретного автора.
Исходя из качественных исследований на активность пользователя влияет размер его аудитории. Моделируем график зависимости Retention от количества подписчиков:
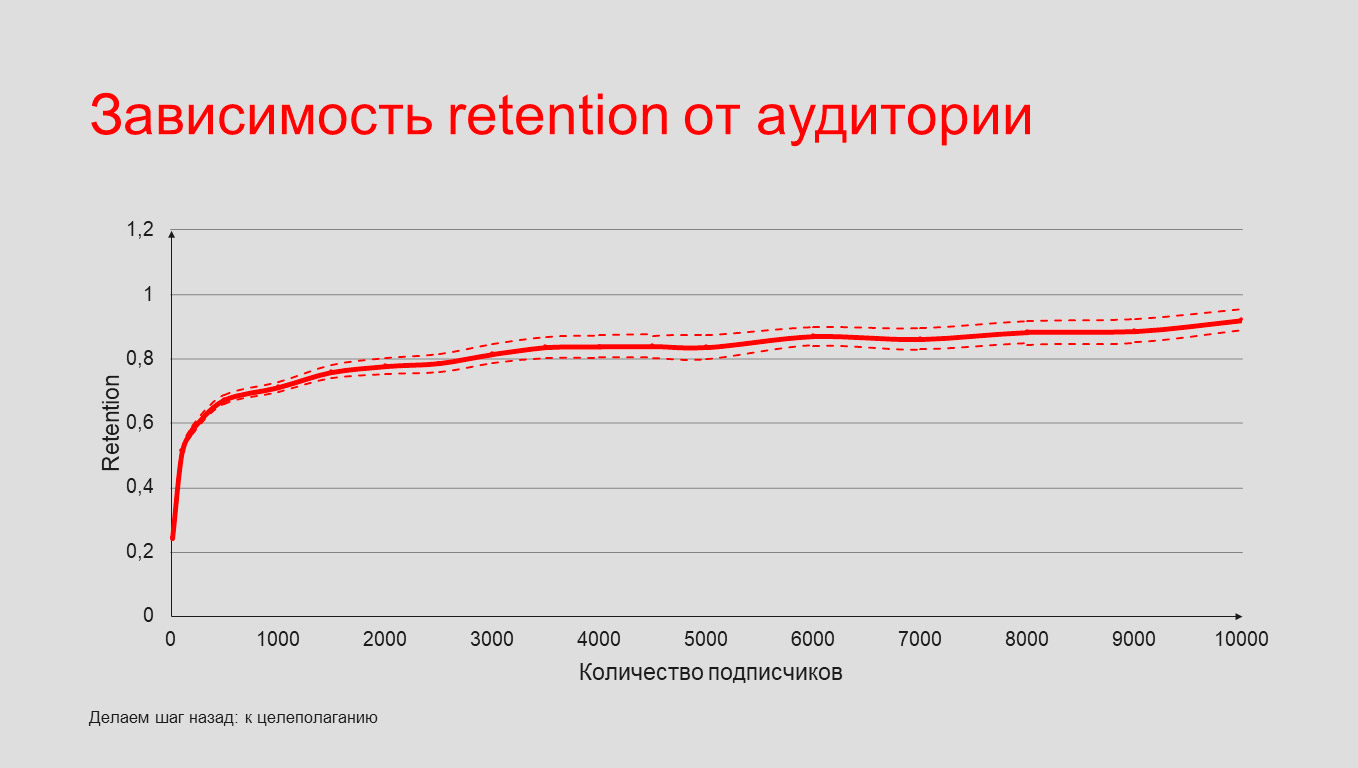
Интересно, что чем меньше подписчиков у автора, тем больше прирастает его Retention. Это логично, потому что для тех, у кого 10 подписчиков, каждый новый более важен, чем для тех, чья аудитория измеряется десятками тысяч.
Этот график даёт ключевую идею, на основе которой мы строили наш механизм ранжирования.
Выписываем ожидаемый WAU — сумму Retention всех авторов в зависимости от количества их подписчиков:

Дальше придумываем, как оптимизировать ожидаемый WAU в каждой пачке:

Смотрим на математическое ожидание дельты количества активных авторов, заносим математическое ожидание под суммирование. Видим, что ожидаемый прирост Retention — это прирост Retention при одной подписке, умноженный на вероятность того, что эта подписка произойдёт.
Запускаем новый механизм ранжирования
Допустим, системе нужно порекомендовать публикацию. На этапе отбора кандидатов есть два автора: один, поменьше, пишет про искусство, второй — побольше, пишет про Китай. Вероятность, что пользователь подпишется на них, разная:

Сначала система рассчитывает, насколько прирастёт Retention в случае подписки. Вероятность подписки определяет модель, которая по паре «пользователь — публикация» предсказывает вероятность того, что данный пользователь подпишется на данного автора с данного айтема. Финальный скоринг — это произведение вероятности подписки на прирост Retention. В таком ранжировании победит автор побольше из-за того, что математически вероятность подписки на него сильно выше.
В итоге наш рекомендательный пайплайн изменился:

Теперь скоринг — это не просто предсказание модели, а предсказание модели, умноженное на изменение Retention.
Прокачиваем отбор кандидатов
Мы увидели следующую точку роста: можно сделать так, чтобы материалы маленьких авторов меньше проигрывали на этапе отбора кандидатов.
В общем виде схема отбора работает так:
- У нас есть какой-то айтем, с которым пользователь позитивно взаимодействовал — например, поставил лайк
- Переходим в данные автора этого айтема и ищем похожих на него маленьких авторов
- С них также набираем какие-то новые айтемы — например, популярные
Для набора похожих авторов можно использовать два подхода.
Контентные похожести → на основе усреднённых контентных векторов публикаций.
Коллаборативные похожести → на основе алгоритма iALS, который определяет тонкости в данных и находит нетривиальные связи.
Мы решили объединить их в единую схему:

С позитивного айтема переходим в автора, дальше делаем переход по iALS-похожести в какого-то другого автора, а потом уже по контенту переходим в маленьких авторов. В этой схеме важно, что слева находятся авторы любого размера. Переход по iALS помогает найти нетривиальные зависимости, а дальше переход по контенту позволяет не учитывать размер авторов справа.
Новый отбор кандидатов помог достичь показателей: +16% подписок на маленьких авторов и +10% показов.
Измеряем результаты
Чтобы измерить, насколько успешно нам удаётся растить WAU, используем систему метрик из двух блоков.
Для экспериментов используем взвешенные подписки → взвешиваем каждую подписку на то, насколько вырос Retention автора.
В длинной перспективе измеряем WAU в A/B-тесте → сравниваем группу авторов, материалы которых ранжируются по новому механизму, и небольшую группу тех, к кому фичу не применяли.
Новый механизм ранжирования помог увеличить WAU на 7%, а измерение прироста Retention позволило нам постепенно снижать долю помогающих показов без падения охватов.