Чем инженерам полезны исследования в рекомендательных системах
Я занимаюсь исследованиями больше четырёх лет и считаю, что инженерам полезно читать исследовательские статьи по двум причинам:
- Статьи расширяют кругозор. В исследованиях обычно обозначают проблемы алгоритмов, которые потом можно встретить в реальных задачах. А ещё авторы делятся опытом, что получилось, что — нет и почему.
- Статьи экономят время. Исследователи проводят эксперименты и предлагают новые методы решения проблем, которые потом можно сразу применять в работе и растить бизнес-метрики в прикладных задачах.
В статьях авторы ищут ответы на разные вопросы. Например:
- Что мы можем рекомендовать конкретному пользователю?
- Почему мы не рекомендовали другие айтемы?
- Почему мы всегда рекомендуем одно и то же?
- Какой долгосрочный эффект у нашей модели на KPI?
- Меняются ли у пользователя рекомендации?
- Как учесть контекст пользователя?
- Как объяснить рекомендации пользователю?
- Как учесть дополнительную информацию об айтеме?
Все важные исследования обсуждаются на конференции ACM RecSys, которая регулярно проходит в разных странах с 2007 года. Дальше в статье расскажу об интересных фактах в рекомендательных системах, некоторые из них будут с конференции 2023 года.
Какие проблемы есть в рекомендательных системах сейчас
Проблемы датасетов в академии
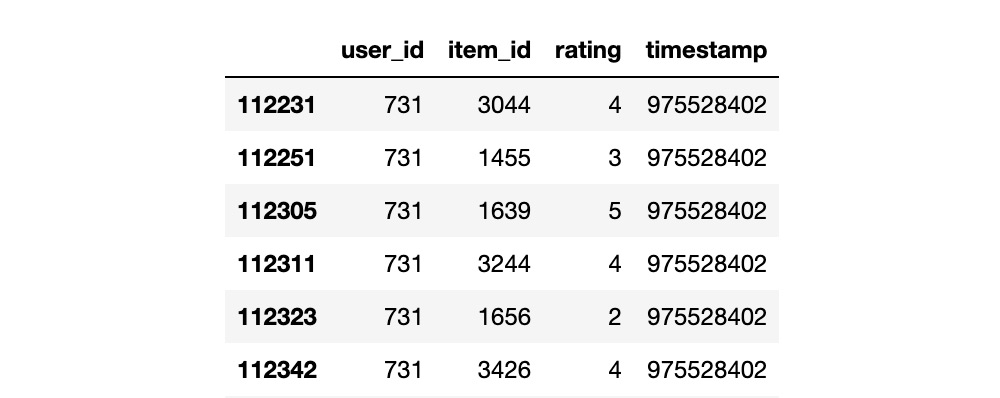
Есть датасет MovieLens 1M. У него примерно миллион интеракций, шесть тысяч пользователей и три тысячи айтемов. В исследовании пользователи MovieLens ставили рейтинги фильмам, и вот какие проблемы в ходе этого обнаружились:
👉 Мало данных для масштабирования. На практике у вас может быть миллион пользователей, миллион айтемов. Модели, которые строят на MovieLens, не всегда можно масштабировать потом на другие датасеты.
👉 Нет дополнительной информации. В MovieLens используют только user/item-матрицу, а на практике есть ещё данные о пользователях, айтемах и других взаимодействиях.
👉 Время интеракций иногда вызывает вопросы. На картинке ниже видно, как пользователь сделал рейтинг за одну секунду. Из этих данных сложно понять, доверять ли таким таймстемпам, как расположить их в правильной последовательности и как предсказывать следующий элемент.
Разные подходы в академии и индустрии
В академии часто просто берут последние элементы и предсказывают следующие. В индустрии нужно выделить таймстемпы так, как это показано на картинке. Всё, что справа, — отдать на тест, всё, что слева, — отдать на обучение.
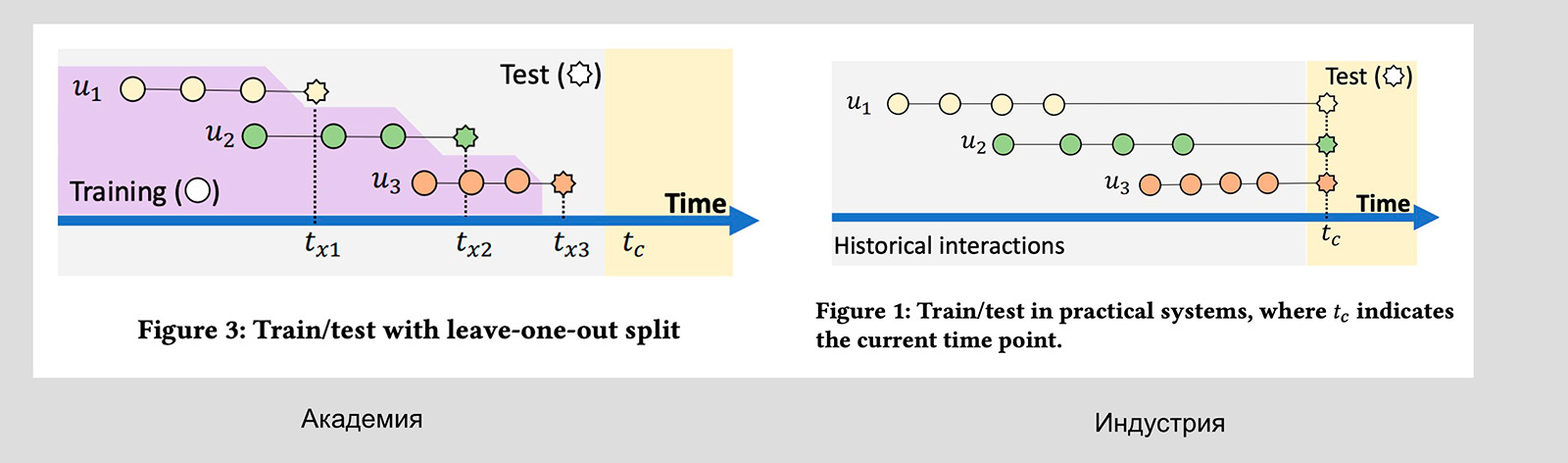
Эти два подхода можно было бы считать эквивалентными, если бы не одно но. В статье Take a Fresh Look at Recommender Systems from an Evaluation Standpoint выяснилось, что разные модели ведут себя по-разному. У одних качество улучшается, у других оно уменьшается. И во всех статьях, где нет global-таймлайна, непонятно, как модели будут вести себя потом в реальности.
Небольшие приросты могут не воспроизводиться
Когда вышли диффузии, захотелось применить их для рекомендаций. Я использовал статью DiffRec с небольшим приростом и выяснил, что на наших данных этот небольшой прирост не воспроизводится. Это немного демотивирует, потому что можно было спокойно сидеть на вариационном тенкодере, который у нас работает, и лучше пока найти трудно.
Как развивались основные подходы в рекомендательных системах в 2023 году
Выход линейной модели SANSA
Мне всегда было интересно, есть ли предел у матричной факторизации. У нас есть пользователи и объекты, мы заполняем значения, кто и что сделал, а потом представляем в виде произведения двух матриц и пытаемся давать рекомендации. В этом нам помогают линейные модели, которые продолжают развиваться. Например, в 2019 году вышла модель EASE, а в 2022 году — ELSA.

В 2023-м появилась модель SANSA. Авторы рассказали, как оптимизировали линейную модель через разложение Холецкого, применили её, и всё заработало.
Эволюция графов в RecSys
В 2021 году вышла статья How Powerful is Graph Convolution for Recommendation?, авторы которой заявили, что графы в рекомендациях необязательно тренировать. Можно взять эмбеддинги юзеров и айтемов, прогнать через граф, и это будет лучше, чем тренированная модель. Потом они пошли дальше и сказали, что всё это можно сделать вообще без эмбеддингов.
В 2023 году вышла ещё одна статья про графы How Expressive are Graph Neural Networks in Recommendation?, которая показала, что можно уменьшить количество кода для реализации граф-модели. Сравните на картинке примеры двух моделей. В модели 2023 года всего восемь строк кода. Но надо понимать, что меньшее количество кода здесь получили только за счёт очень сложной математики.

Выход gSASRec
Посмотрите на картинке, как использовали SASRec в 2018 году. Мы последовательно идём по действиям пользователей, предсказываем следующий элемент, пытаемся максимизировать вероятность положительного действия и минимизировать вероятность случайно негативного элемента.

В 2023 году вышла ещё одна интересная статья Александра Петрова gSASRec: Reducing Overconfidence in Sequential Recommendation Trained with Negative Sampling, где он предложил добавить в лосс некоторый коэффициент, который позволяет откалибровать вероятности. На графике можно увидеть, как он проходит по линии Y и X и показывает предсказанную и реальную вероятности. Так, например, можно получать ожидания условной прибыли от рекомендации айтема.

Какие тренды появились в рекомендательных системах в 2023 году
ChatGPT может быть рекомендательной системой
Если вы откроете ChatGPT, напишете, что вам нравится, и попросите порекомендовать что-то похожее, он предложит варианты. Это такая независимая рекомендательная система, которой может пользоваться каждый.
Для реального использования ChatGPT подойдёт вряд ли. Во-первых, это платно, во-вторых, может внезапно перестать работать, в-третьих, ChatGPT нельзя передавать чувствительные данные о пользователях, в-четвёртых, он не так быстро работает для продакшена.
Можно делать finetuning LLM под RecSys
Тем не менее большие языковые модели потихоньку заходят в рекомендательные системы. Уже есть много различных способов, как делать finetuning для моделей, чтобы модель умела решать какие-то задачи для рекомендаций.
Примеры статей с названием LLMRec, которые подтверждают тренд:
- LLMRec: Large Language Models with Graph Augmentation for Recommendation
- LLMRec: Benchmarking Large Language Models on Recommendation Task
- LLM-Rec: Personalized Recommendation via Prompting Large Language Models
- A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems
Эмбеддинги айтемов ChatGPT тоже помогут
Есть более простой и понятный для меня способ, чем finetuning LLM под RecSys. Например, мы можем инициализировать эмбеддинги айтемов и дальше запускать уже известные последовательные модели.
В статье Leveraging Large Language Models for Sequential Recommendation авторы взяли эмбеддинги для каких-то объектов, инициализировали BERT4Rec и показали, как это помогло сойтись с наиболее оптимальным результатом.

RL продолжают встраивать в RecSys
Ещё в 2020 году вышла статья Self-Supervised Reinforcement Learning for Recommender Systems, в которой рассматривали задачу next item recommendation, когда мы пытаемся предсказать следующий исторический токен. Авторы статьи просто взяли реальный подход, немного накрутили его на RecSys и получили статью, которая собрала 150 цитирований.
Продолжают появляться и другие статьи с использованием RL. Одни авторы рассматривают моделирование бизнес-процессов и влияние рекомендаций на улучшение метрик. Примеры статей:
- User Retention-oriented Recommendation with Decision Transforme
- Reinforcing User Retention in a Billion Scale Short Video Recommender System
- Interpretable User Retention Modeling in Recommendation
Другие показывают, как они используют подходы из RL, и публикуют результаты A/B-тестов. Примеры статей:
- Nonlinear Bandits Exploration for Recommendations
- Contextual Multi-Armed Bandit for Email Layout Recommendation
Из этого можно сделать вывод, что RL остаётся в тренде в 2023 году.