Что такое DataLens
DataLens — BI-система для анализа и визуализации данных. BI (business intelligence, бизнес-разведка) используется бизнес-аналитиками для того, чтобы перенести большие объёмы данных в базах данных на чарты (графики), собрать их в дашборды и быстро оценить информацию.
Архитектура. Есть много разных источников данных, например ClickHouse, PostgreSQL. Данные собирают через подключение в датасеты, датасеты — в чарты, и всё это укладывается на дашборд в режиме реального времени.
Осенью 2023 года DataLens объявили о выходе в open source. Это означает, что вы можете взять исходный код по ссылке, форкнуть его и использовать в своём продукте.
Зачем нам open source
Открытость и вклад сообщества. Яндекс верит в открытость и в то, что для поддержания баланса должен участвовать в опенсорс-разработке, поскольку сам использует подобные решения. Также компания ожидает вклад сообщества: разработчики могут закинуть пул-реквест на GitHub, и фича появится в облачной версии DataLens.
Возможность развернуть DataLens в любой инфраструктуре. Даже на собственном ноутбуке. Для многих пользователей это важное преимущество.
Рост популярности и техно-PR. Появляется много статей и обсуждений, люди начинают смотреть на продукт с бóльшим интересом. То есть это чистый Tech PR — и теперь можно даже позвать кого-то на работу, а человек уже заранее может посмотреть код продукта и увидеть, что в нём нет хитрых велосипедов.
Упрощение аудита. Очень часто в open source выходят, чтобы работники службы безопасности посмотрели на код.
Улучшение качества кода и оздоровление кодовой базы. Как только вы выходите в open source, код нужно проверить, убрать костыли или библиотеки, которые не хотите показывать. Это хороший повод обновить устаревшие части кода.
Как раскрывали код
DataLens изначально развивался как внутренний продукт, у которого минимум два бэкенда на Python со своей базой данных.
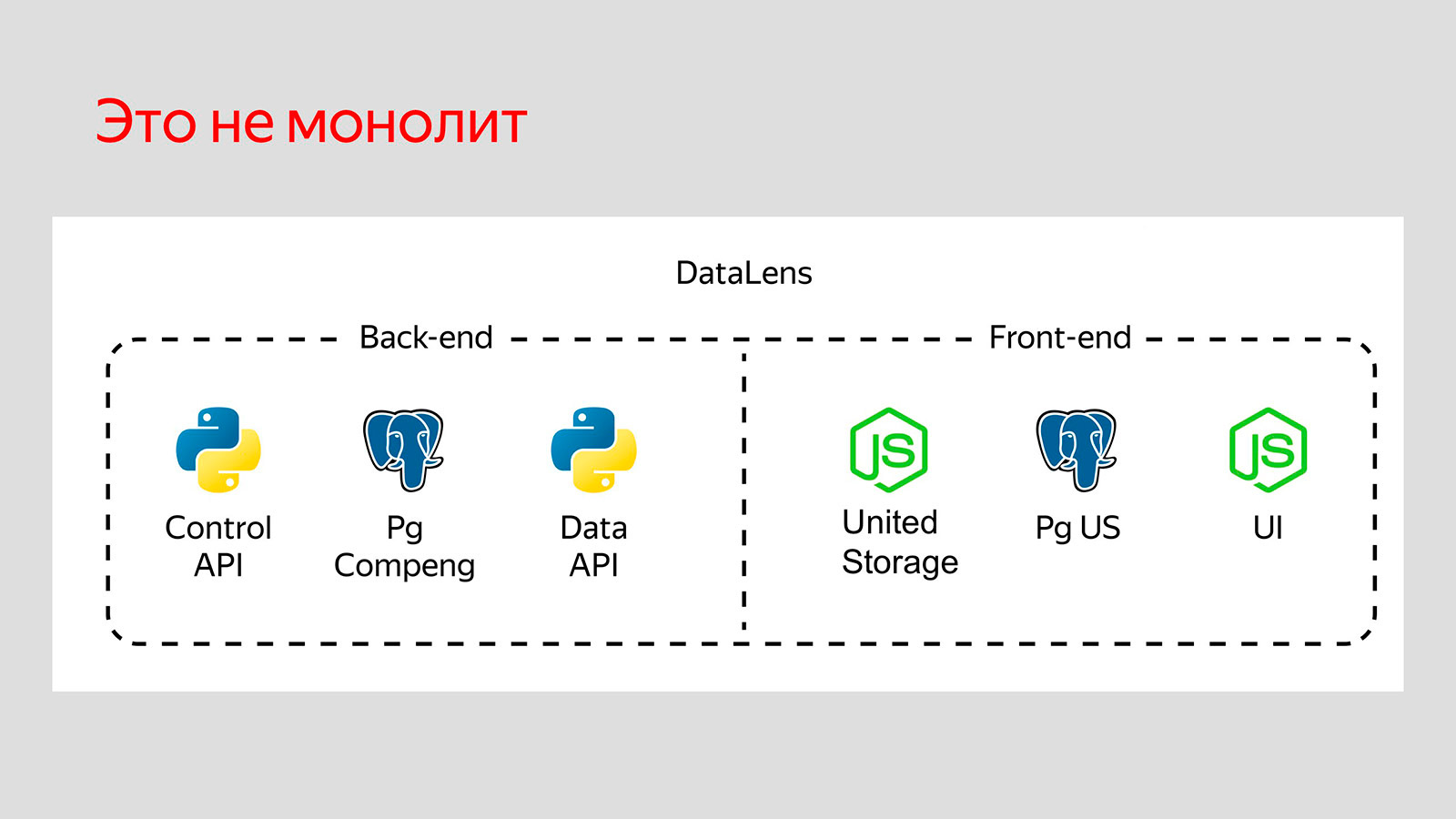
Нужно собрать вместе две Node.js, два Python и две базы данных и дать людям возможность попробовать продукт у себя без проблем с установкой.
В репозитории DataLens практически один файл docker-compose.yml, остальное — документация и конфиги. Docker-compose.yml — одновременно и конфигурация как код, и документация. Достаточно запустить команду docker-compose up.
Open Core. Команда разработки решила, что будет выкладываться по модели open core. Это значит, что в open source есть базовая функциональность, а дополнительной нет. Она предоставляется, например, за деньги проприетарными аддонами.
«Однонаправленный» open source. Нередко open source от крупных компаний выглядит так: есть внутренний репозиторий и наружу делается зеркало. В самом базовом варианте этот код даже нельзя собрать, а в варианте получше его можно собрать и использовать, но пул-реквесты не принимаются.
Yandex Cloud хотела получать вклад сообщества, поэтому в компании решили полностью перенести разработку из монорепозитория на GitHub. План был простой:
- Посмотреть на все зависимости и поменять те, у которых неподходящие лицензии. Часть внутренних пакетов раскрыть и вывести в open source — этот процесс начали гораздо раньше, чтобы потом собрать из них большие продукты.
- Придумать механизм расширения открытого ядра проприетарным кодом.
- Выложить всё на GitHub и настроить CI.
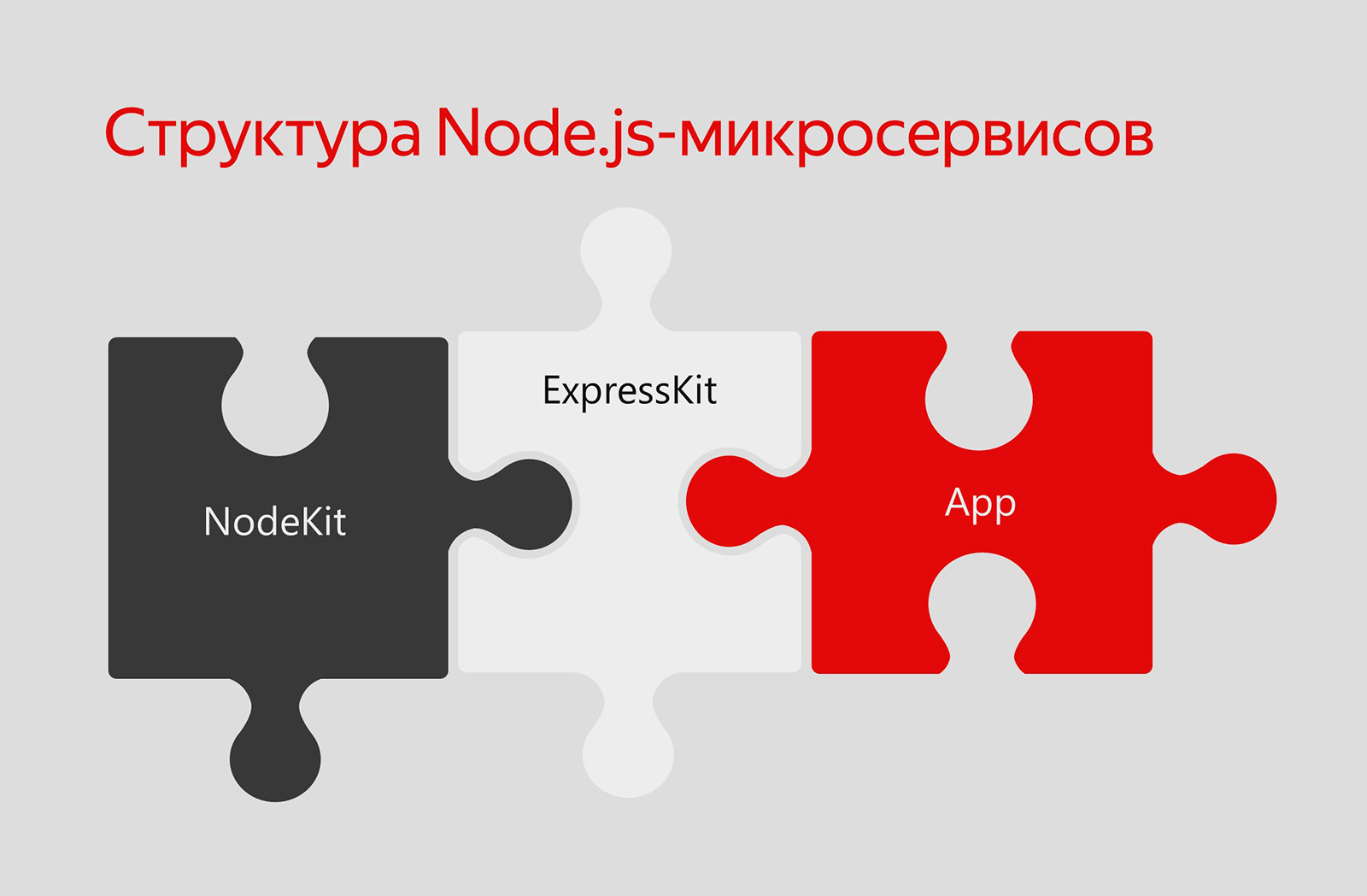
Gravity UI. Gravity UI — красивая дизайн-система Yandex Cloud, компоненты которой можно использовать для сборки собственных продуктов. Есть UI- и Node.js-библиотеки, а также инфраструктурный код (ESlint Config, TSconfig). Для начала выложили полностью Gravity UI в open source.

Потом пересобрали DataLens на открытых библиотеках. То есть DataLens можно представить как слоёный пирог из NodeKit, ExpressKit и бизнес-логики.
Команда DataLens рассматривала несколько вариантов, как технически вывести продукт в open source: думали просто форкнуть код либо поставить npm-модуль. По разным причинам это не подошло, поэтому решили использовать нестандартное решение — взять open source репозиторий и вложить его внутрь проприетарного репозитория.
Оказалось, что IDE прекрасно работают с такими вложенными репозиториями: вы открываете ваш редактор кода, и он видит, в какую папку вы сделали изменения, и предлагает сделать пул-реквест. Но из-за этого появились и минусы: это нестандартный подход с точки зрения фронтенда, нет версионирования, код завязывается на файловую структуру.
Чтобы сделать схему стабильной, нужно версионировать код опенсорс-ядра, версия должна обновляться через пул-реквест, а PR — запускать интеграционные тесты. Эту задачу тоже решили: просто добавили в репозиторий файл datalens-platform-version, небольшой скрипт на Bash читает этот файл, определяет нужную версию, клонирует из Git платформу и потом переключается в ту ветку, то есть наша версия — это просто ветка вложенного репозитория.
Как подменить реализацию. Есть два способа: Dependency Injection и Service Locator. Второй сейчас считается антипаттерном, но это удобно.
Настоящую Dependency Injection даже внутри TypeScript сделать сложно: нет интерфейсов, которые живут в рантайме. В итоге использовали Service Locator. Взяли registry, зарядили в него изменённую версию, и когда её использовали, уже подтягивалась изменённая.
Ещё одна задача как пример проблем. Исчезает механизм работы с package.json, нет возможности поставить зависимости из этого репозитория наружу. Внутри источник правды, а снаружи должно быть расширение. У package.json нет такого механизма, поэтому пришлось делать вручную — создали линтер. Взяли первый и второй package.json, написали из них компоратор, который смотрит dev-, peer- и продакшен-зависимости. Если всё хорошо, то exit 0.
Это был минимум для того, чтобы выложиться в open source, и оно работало. Но возникло ещё очень много задач.
Процессы, тесты и некодовая контрибуция
Процессы. До того как ваш продукт появился в open source, в компании была внутренняя Jira или трекеры, где ставили задачи. Теперь появляются GitHub Issue. И люди из внешнего мира начинают приносить GitHub Issue.
Ваши Issue внутри тоже должны прорастать, нужно подробно описывать ваши пул-реквесты, вести CHANGELOG.MD. Люди, которые пользуются open source, должны понимать, для чего прилетает пул-реквест. Нельзя просто поставить ссылку в Jira или тред в Slack. Журнал изменений очень важен, потому что разработчики продукта должны понимать, по какой причине, например, поднимается мажорная версия.
Нужна хорошая публичная дорожная карта. Люди должны понимать, что будет с опенсорс-проектом через год или даже через два, чтобы понять, можно ли на него завязывать свой бизнес.
Тесты. Ещё меняются тесты. Весь DataLens покрыт E2E-тестами, которые завязаны на инсталляции, но инсталляции не похожи. Нужно поддерживать столько E2E-тестов, сколько появляется инсталляций. Плюс ещё open source — тоже отдельные E2E-тесты. При этом мало тестов шарятся между инсталляциями, то есть их становится больше.
Как убедиться, что новое ядро с пул-реквестами совместимо с проприетарными аддонами? Есть GitHub Actions в GitHub. Пришёл пул-реквест — запустили lints, Typechecks, Unit tests, E2E-тесты и проверили ядро open source.
Одновременно во внутреннем CI можем запустить checker. Он увидит, что пришёл пул-реквест, возьмёт ядро, добавит к нему аддоны и запустит все тесты на них. Таким образом, всегда будем знать, как пул-реквест влияет на закрытые расширения.
Это решение масштабируется, если в разные компании поставить такие аддоны. Можно даже обратно в GitHub нарисовать результаты этих тестов.
Получается процесс обновления ядра:
- Приходит пул-реквест. Внутренний CI проверяет интеграцию PR из внешнего репозитория с проприетарным кодом.
- Если PR пришёл от внешнего контрибьютора, автотесты во внутреннем контуре не запускаются — это небезопасно, поэтому PR от внешних контрибьюторов проверяем вручную.
- Мейнтейнеры кода принимают решение — допускать ли добавление ломающих изменений или нет.
Некодовая контрибуция. Во-первых, это документация. Бизнес-аналитики, которые пользуются вашим продуктом, могут заметить, что где-то документация неполная или её можно раскрыть интереснее. Они должны иметь возможность законтрибьютить документацию. Во-вторых, тексты и переводы. Это тоже важная часть продукта.
Всё это становится проблемой, когда вы выходите в open source.
Как её решали. Документация лежит в md-файлах. Можно зайти в репозиторий, найти md-файл и сделать пул-реквест.
Воспользовались Diplodoc — это ещё один опенсорс-продукт от Yandex Cloud, который направлен на создание технической документации в концепции Docs as Code. Используем его как CLI-системы. Все пул-реквесты, которые приходят в документацию, будут синхронизированы с облачной документацией.
Переводы. Если ваш продукт мультиязычный, мы не вставляем фразы на нужном языке, а просто вставляем ключи, которые уже ведут на необходимую нам фразу на выбранном языке. Появляется много файлов, в которых лежат переводы и ключи.
Как с этим работают. Разработчик делает пул-реквест. CI смотрит, что в пул-реквесте изменились тексты, отправляет это в сервис, который работает с переводами. Переводчик смотрит на ключи и переводит. Например, если текст изменили на русском, надо изменить его на английском.
Дальше появились новые ключи, они возвращаются в репозиторий. После этого можно влить пул-реквест в main. Так работают системы непрерывной локализации. Наше отличие — работаем с ветками, а не вешаем прямо на main или отдельно создаём языковые пул-реквесты.
Во внутреннем контуре в Яндексе был собственный сервис. Возникает проблема: человек сделал пул-реквест и не понимает, почему тот не вливается. От внутреннего сервиса тоже приходится отказываться при выходе в open source. Задача ещё в процессе, скоро переводы будут работать через публичный сервис.
Итоги
Промежуточные итоги работы:
- 1 100 звёзд на GitHub.
- Заявили о себе в профессиональной среде — многие стали больше рассматривать DataLens как систему для BI, потому что у продукта есть опенсорс-версия.
- Процесс разработки усложнился — делаем пул-реквест не в один репозиторий, а минимум в два. Стало больше тестов.
- Возможность показать код, поделиться ссылкой в телеграм-канале.
Что будет дальше
Впереди у команды много задач. Нужно:
- Научиться работать с Issue
- Создать дорожную карту
- Создать API для расширений
- Научиться публично документировать свою работу
- Перейти на semver и выпустить версию DataLens 1.0
- Подумать о потенциальной монетизации