Как изначально выглядела система и почему решились на изменения
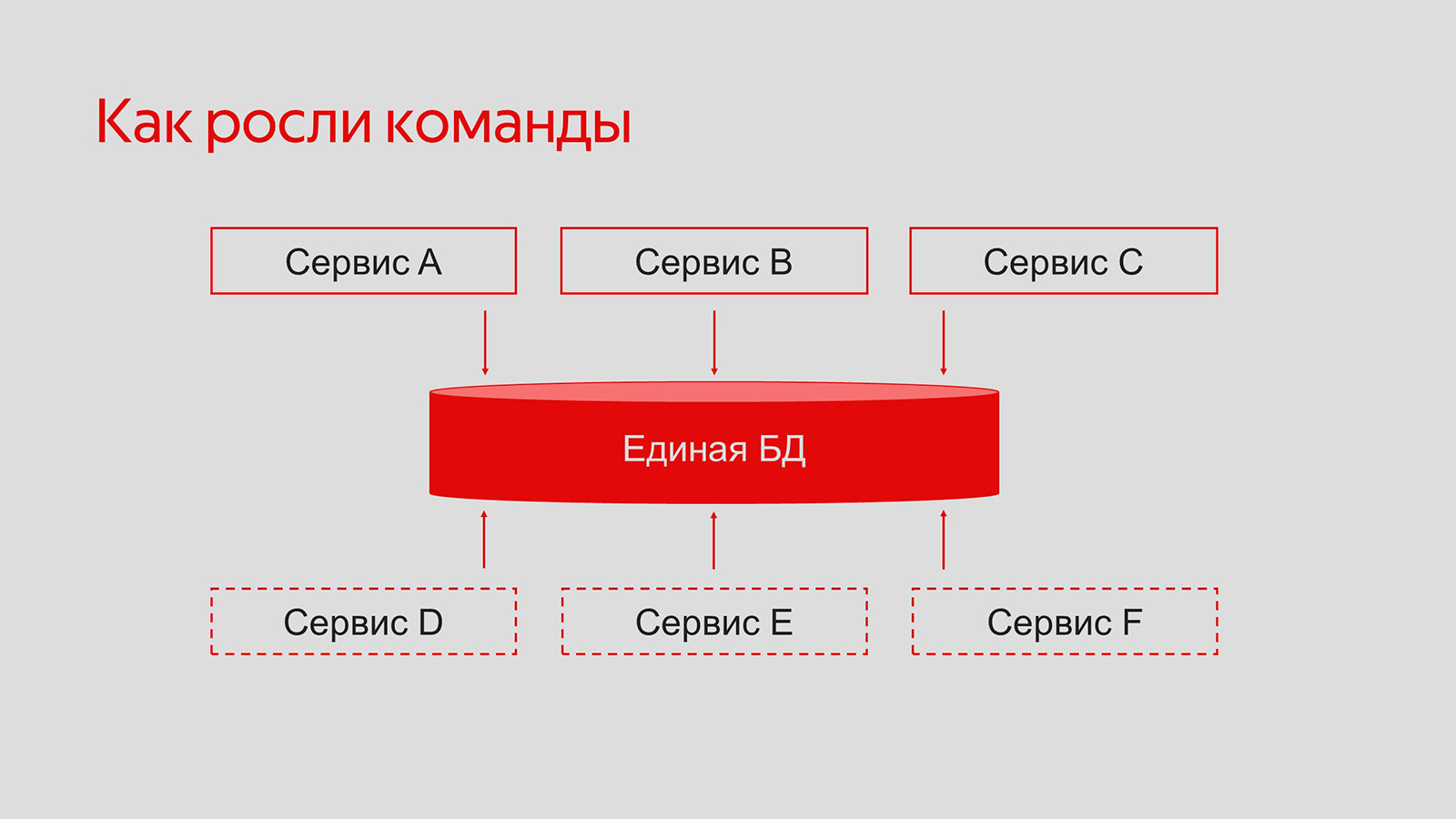
Я уже два года работаю в отделе программ лояльности банка «Тинькофф» — в команде начисления кешбэков. Сервисы в моём отделе начали разрабатывать порядка шести лет назад. Тогда ещё не было понятно, насколько масштабной окажется эта история и какой будет нагрузка, поэтому все сервисы подсаживались на единую базу данных.

Потом система разрослась: увеличилось количество команд, бизнес-сценариев и сервисов, которые мы разрабатывали. Но база по-прежнему оставалась общей.
Количество пользователей Тинькофф тоже быстро росло: в 2020 году было около 13 млн, а летом 2023 года перевалило за 35 млн. Нагрузка на наши сервисы, как и на другие сервисы банка, увеличилась.

Чтобы уменьшить связанность элементов и увеличить отказоустойчивость системы, данные решили разнести по разным хранилищам.
Вот требования к системе, от которых мы отталкивались:
- Простота в поддержке и мониторинге
- Высокая скорость обработки запросов
- Консистентность, но не обязательно в моменте
- Отказоустойчивость
Почему нельзя просто распилить базу данных на несколько
Самый простой вариант — распилить БД между сервисами: у сервиса А — своя база данных, у сервиса Б — своя. Так мы улучшаем отказоустойчивость и равномерно распределяем нагрузку, но есть одно но — связи в модели данных.

Допустим, у нас есть сервис данных о клиенте и сервис обработки переводов. Раньше данные этих сервисов хранились в единой базе. Если сервису обработки данных требовалась какая-то информация о клиенте, он мог сходить в соседнюю табличку. Но теперь, когда мы разделили базы, перед нами встал вопрос: как сервису обработки переводов получить информацию о клиенте. Прежде чем решать проблему, мы проанализировали, какие вообще есть варианты.
Какие решения отвергли
Мы рассмотрели шесть вариантов и пять из них отбросили. Начнём с них.
Обращение в чужую базу данных
Первое, что приходит на ум, когда сервису нужно получать данные из чужой базы, — получать их из неё напрямую. Так у нас остаётся всё тот же сервис данных о клиенте и всё тот же сервис обработки переводов. Настраиваем коннект от сервиса обработки переводов к базе данных клиентов — и готово!

Плюсы:
- Мы нашли простое и быстрое решение и теперь можем получать данные из чужой базы.
Минусы:
- Отсутствие гибкости. Если сервису данных о клиентах потребуется внести изменения в модель данных, он должен будет согласовать их со всеми зависимыми системами.
- Основная проблема всё ещё не решена: нагрузка по-прежнему осталась на одной таблице в базе данных.
- Доступность системы ограничена. Если для выполнения оперативной задачи сервису обработки переводов потребуются данные из БД клиентов, а она по какой-то причине упала, сервис переводов не сможет корректно обработать запрос.
Не будем забывать, что такие идеи быстро завернёт служба безопасности с вопросом: «Зачем вам такие доступы?»
Обращение в сервис по API
Чуть менее радикальная идея — обращаться не напрямую в БД клиентов, а через внешний API этого сервиса.

Плюсы:
- Разделяем модели данных разных сервисов: теперь сервис данных о клиенте может как угодно менять модель данных в своей базе, и работа всей системы из-за этого не сломается.
Минусы:
- Необходимо поддерживать внешний контракт.
- Доступность системы всё ещё ограничена.
- Запросы дольше обрабатываются, потому что теперь их нужно пропускать через отдельный сервис.
Встроенная репликация в СУБД
Мы поняли, что хотим улучшить доступность системы, чтобы сервисы работали независимо друг от друга. Решили изучить готовые решения, чтобы не изобретать собственный велосипед.
На базе СУБД можно сделать Master-Slave репликацию. Каждый сервис будет работать со своей базой и менять в ней данные как ему нужно, а СУБД сама будет реплицировать их в Slave-ноды, к которым будут обращаться зависимые сервисы.

Плюсы:
- Простота доработок со стороны кода.
- Большая доступность сервисов относительно предыдущих решений.
- Более равномерное распределение нагрузки по инстансам базы данных.
Минусы:
- Необходимость подключения к нескольким СУБД. Каждому зависимому сервису пришлось бы поддерживать коннекты к разным базам данных — к своей основной БД и к readonly-репликам, куда приходят данные из других мастер-систем.
- Отсутствие поддержки OLAP-нагрузки. Мы ориентируемся на решения базы данных OLTP, например Oracle или PostgreSQL. Если у нас появится сервис, которому нужно будет поддерживать OLAP-нагрузку, непонятно, что с этим делать.
- Процесс репликации данных непрозрачный, а мы бы хотели логировать или каким-то иным образом мониторить, когда данные дошли до зависимых систем.
- Невозможность выполнять бизнес-логику приложений. Например, у нас в приложении существуют in-memory кеши, которые мы хотели бы инвалидировать при получении новых данных.
GoldenGate и аналоги
На рынке существуют решения по отправке данных из одной СУБД в другую, например Oracle GoldenGate и его аналоги.

Плюсы:
- Не требуется серьёзных доработок со стороны кода.
- Увеличена доступность сервисов.
- Равномерно распределена нагрузка на слой хранения данных.
- Возможна поддержка разных технологий хранения данных: в отличие от предыдущих решений, мы можем переливать информацию, например, из Oracle в ClickHouse.
Минусы:
- Непрозрачный процесс репликации.
- Нет возможности выполнять какую-либо бизнес-логику при получении данных, либо это потребует серьёзных доработок со стороны кода. При этом необходимость в сбросе in-memory кешей всё ещё присутствует.
Распределённая транзакция
Чтобы применять изменения данных сразу к нескольким базам, решили рассмотреть распределённую транзакцию.

Например, пусть в нашей архитектуре мастер-системой является сервис admin, который отправляет свои данные в зависимые сервисы cashback и client. Сервис admin применяет изменения к своей базе данных, а затем должен удостовериться, что зависимые сервисы — cashback и client — тоже применили эти изменения к своим БД. Если какой-то из сервисов недоступен, мастер-система должна откатить эти изменения
Плюсы:
- Консистентность данных в моменте.
Минусы:
- Сложно реализовать конкретно под наш проект.
- Нужны доработки при добавлении каждого нового сервиса в систему.
- Низкая доступность системы: невозможно сохранить изменения в мастер-систему, если один из зависимых сервисов недоступен.
- Не всегда можно полноценно откатить транзакцию, если зависимый сервис оказался недоступен. Некоторые действия могут иметь side-эффекты, например отправка письма по почте.
На каком решении остановились
В итоге мы приняли решение сделать асинхронную репликацию данных через Kafka.

Всю репликацию через Kafka можно поделить на три основных шага:
→ Данные сохраняются в мастер-систему
→ Отправляются в Kafka
→ Зависимые сервисы получают информацию из Kafka и применяют изменения к своим копиям данных
Так мы смогли развязать модели данных между мастер-системой и зависимыми системами. Например, если мы из сервиса admin передаём какую-то сущность, где сотни полей, а в сервисе кешбэка нам нужно лишь четыре из них, мы легко можем сохранять только эти четыре поля, а остальные — игнорировать.
Ещё один плюс — разделение зон ответственности. Сервис admin ответственен только за то, чтобы сохранить данные в свою базу и отправить их в Kafka, а зависимые сервисы — за то, чтобы считать информацию из Kafka и применить к своим копиям данных.
Зачем ввели версионированность
Чтобы во всех базах данных хранилась самая актуальная информация, мы ввели версионирование сущностей.
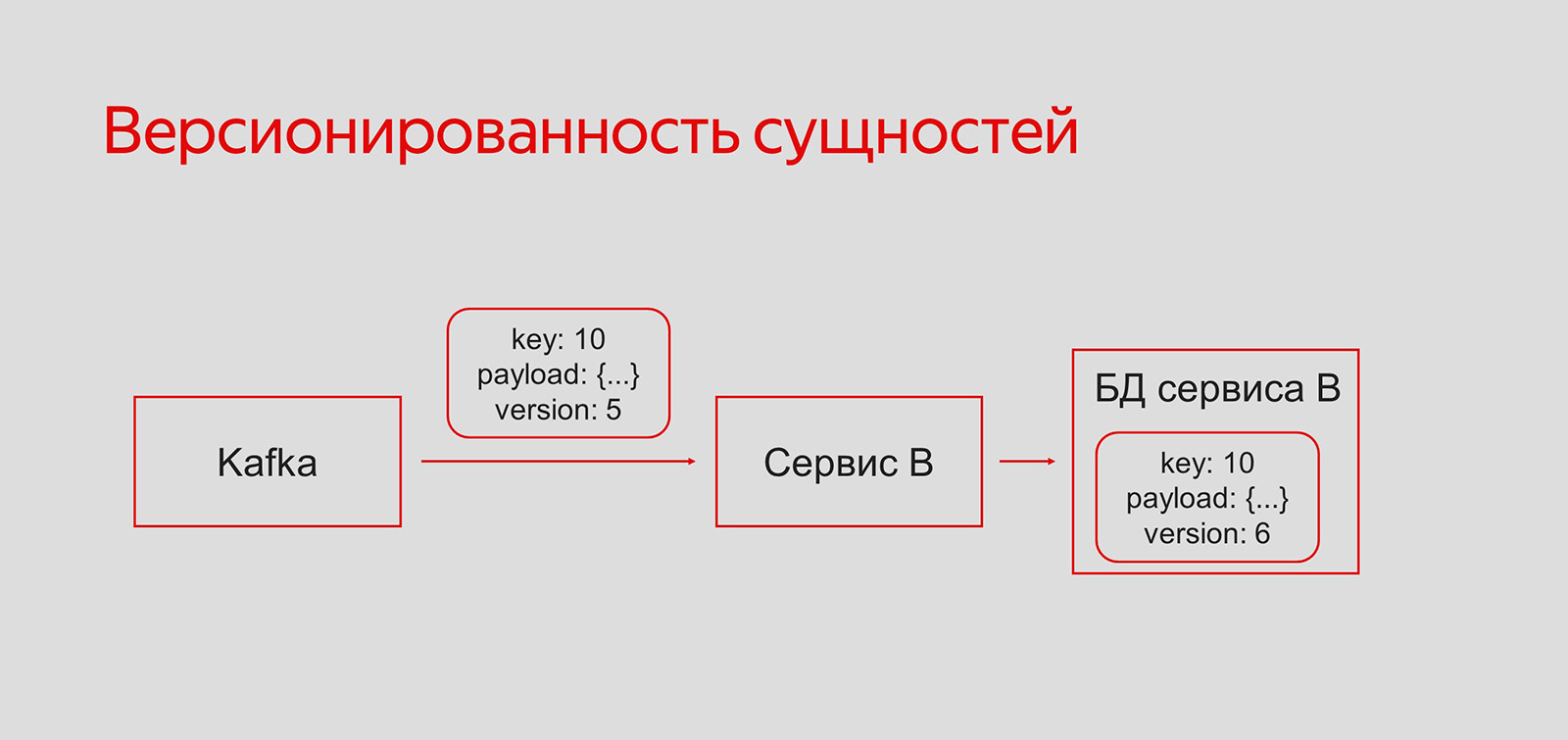
У каждой сущности есть поле version, которое говорит нам о том, какая версия на текущий момент наиболее актуальна.
Допустим, по какой-то причине в системе произошёл reordering сообщений. Сервис cashback прочитал запись version:5, притом что в его базе лежит более актуальная — version:6. В таком случае он просто пропустит устаревшую запись и не произведёт никаких изменений в своей базе, поскольку поймёт, что произошёл reordering сообщений.
Какой подход к хранению и отправке данных выбрали
Существует довольно популярный паттерн Event Sourcing по отправке сообщений, но от его дефолтной реализации мы отказались.
Дело в том, что классический Event Sourcing представляет данные в системе как последовательность их изменений. Например, у нас создан новый банковский счёт с нулевым балансом. Дальше идёт череда пополнений и списаний. Чтобы посмотреть текущее состояние счёта, необходимо к стартовому состоянию применить все изменения, которые были произведены.

Проблема такого подхода — скорость отправки исторических данных.

Сравним два подхода к отправке данных: отправку всех изменений данных и отправку слепков данных. При одном и том же количестве сущностей и их изменений в случае хранения и отправки только слепков данных мы получим значительно большую скорость процесса репликации исторических данных.
Другая проблема классического Event Sourcing — потеря сообщений. Если в системе не будет механизма перезапроса данных и при отправке потеряется хотя бы одно сообщение, мы можем получить неправильное состояние в зависимой реплике навсегда. В то время как при отправке данных целиком мы просто на какое-то время останемся с не самыми актуальными данными, и когда сущность изменится в следующий раз, мы прочитаем изменения и вернём согласованность данных.

Поскольку версионированность решила проблему с изменением порядка сообщений, отправка данных целиком выигрывает по четырём критериям из пяти.
Что получилось
Проверяем, соответствует ли решение тем требованиям, которые мы сформулировали изначально.
Простота поддержки и мониторинга
Архитектурно наше решение довольно простое. Мы можем добавить логирование и мониторинги куда хотим, потому что написали репликацию сами на уровне нашего приложения.
Высокая скорость обработки запросов
Для быстрой обработки большого количества запросов у нас есть внутренние кеши в подах приложения.
Записывая в базу новые данные, мы должны инвалидировать кеши на всех подах приложения, чтобы поддерживать их в согласованном с БД виде. Если не сбрасывать кеши, пользователи будут получать актуальную информацию по счёту с задержкой. Если не синхронизировать кеши между подами, ситуация будет ещё интереснее: в зависимости от того, к какому поду подключается клиент, он будет видеть то одну информацию, то другую.

Синхронизация кешей выглядит следующим образом. Один из подов приложения вносит изменения в БД. Затем он сбрасывает свой кеш и через специальную очередь для синхронизации кешей отправляет другим инстансам сообщение о том, что им тоже необходимо сбросить такие кеши. Так мы и держим кеши в согласованном состоянии между разными инстансами.
Консистентность, но необязательно моментальная
Такой подход к репликации данных приводит нас к eventual consistency. То есть в системе возможна временная несогласованность данных.
Чтобы избежать несогласованности и ошибок в расчётах, у нас есть регулярная операция по проверке корректности данных. Мы создали сервис, который видит все транзакции и раз в несколько дней перепроверяет вычисления. Каждый месяц он составляет документ, где отражаются все транзакции пользователя и информация по ним. Такими регулярными проверками мы делаем наши ежемесячные отчёты корректными.
В среднем доставка обновлений до конечных зависимых систем занимает порядка 1–2 секунд. Если что-то идёт не так — в одной из систем скопился большой лаг или сообщения лежат очень долго, — срабатывают алерты.
Отказоустойчивость
Разделив слой хранения данных на разные БД, мы увеличили доступность и устойчивость системы к отказам. На каком бы участке ни возникла проблема, она не выведет из строя всю систему. Рассмотрим все три возможных сценария.
Мастер-система

Если мастер-система недоступна, например отвалился коннект к базе данных, зависимые сервисы продолжают работать каждый со своей копией данных. На время недоступности мастер-системы у пользователей не будет возможности вносить изменения в данные, но при этом остальные сервисы продолжат корректную работу. После восстановления мастер-системы возможность вносить изменения в данные и реплицировать их вернётся.
Kafka

Если недоступна Kafka, мастер-система продолжает корректно обрабатывать запросы на изменение данных и сохраняет их в свою БД. Отправлять данные она не может, но у себя копит. Когда Kafka вновь станет доступна, мастер-система отправит туда обновления, зависимые сервисы их считают, и система вновь станет согласованной.
Зависимые системы

Если станет недоступной одна из зависимых систем, например система cashback, это никак не повлияет на остальные. Мастер-система всё так же будет получать обновления, сохранять их у себя и отправлять в Kafka, а зависимые сервисы продолжат вычитывать их из Kafka. Когда система cashback восстановится, она сможет прочитать все те сообщения, которые были отправлены в период её недоступности.
Что всё это значит для пользователей:
- За счёт того, что в системе используются in-memory кеши, она работает быстро.
- Благодаря тому, что мы умеем инвалидировать кеши, данные в приложении отображаются корректно.
- Для критичных расчётов есть механизм перепроверки, поэтому пользователи получают надёжный сервис.
- Мы разделили источники данных между разными базами данных: даже если с одним из них что-то случится, вся остальная система будет работать корректно, и пользователи, возможно, даже не заметят сбоя.
Подробнее об особенностях итогового решения и дополнительных сложностях, с которыми столкнулись инженеры Тинькофф, можно узнать из выступления спикера.