Конечная цель продукта — сделать пользователя счастливым. Для этого нужен крутой бэкенд. Он отвечает четырём критериям:
- Стабильный
- Оптимальный по железу
- Поддерживает нормальную скорость добавления фич
- Может эволюционировать
В этом докладе мы подробно остановимся на последнем пункте. Рассмотрим эволюцию продукта на примере стартапа, компании среднего класса и корпорации. Обсудим проблемы, которые «болят» на каждом из этих этапов.
Стартап
Среднестатистический стартап — это бэкенд-сервис, база данных и пачка внешних запросов. На этом этапе развития важно не переусложнять инфраструктуру.
Если вы стартап внутри большой корпорации и у вас есть отдел, который создаёт под вас инфраструктуру, — это хорошо. Но всё равно не нужно продумывать, какими крутыми вы будете через три года и какая инфраструктура вам тогда понадобится. На начальном этапе развития главная задача — понять, как экспериментировать и разрабатывать быстро с помощью той инфраструктуры, которая отвечает вашим нуждам сейчас.
Вредный совет: купить или арендовать пачку железных серверов и после этого начинать всё поднимать с нуля. Скорее всего, вы потратите огромное количество усилий на поддержание, вместо того чтобы заниматься реально важными вещами. В архитектуре, как ниже, нет ничего плохого.

Иногда стартаперы осознают, что у них есть продукт, но они не используют в нём высокие технологии, о которых рассказывают на конференциях. Кажется, что компания недостаточно хороша. Но на самом деле стартап успешен, пока его продукт востребован у пользователей.
Часто инфраструктуру делают на будущее — всё равно потом понадобится эволюционировать. Чтобы понять, почему этот подход не совсем верный, рассмотрим пример тыквы и Apphost.
Тыква и Apphost
Тыква — это сервис-заглушка. Если основной сервис в геозоне или глобально не отвечает, делается запрос во что-то простое и независимое по инфраструктуре, которое всегда работает и решает 80% нужд пользователя. Например, для Поиска это просто статические HTML-страницы — находим ближайшую по запросу и отдаём.
Apphost — это конфигурируемый API gateway. В Яндексе поверх него работают Поиск, Картинки, Погода и ещё несколько больших сервисов.
Конфигурация Apphost — это граф. Его вершины — сервисы, а рёбра — зависимость по данным. Это похоже на фреймворки обработки данных, где перекладывают логи.
На самом деле Apphost большой и сложный. Изначально он зародился как поисковая инфраструктура. Поиск — это больше 10 000 машин, свыше 5 000 поисковых запросов в секунду и около ста микросервисов на пути запроса.

Иногда приходят коллеги и говорят: «Давайте сделаем тыкву на Apphost. У нас есть далекоидущие планы, может быть, распилимся на микросервисы». Это желание понятно, и разработчики приступают.
Получается такая конфигурация: запрос уходит в основной сервис, появляется ответ. Если сервис не ответил, запрос уходит в тыкву и ответ выдаёт уже она.

Проблема в том, что бизнес-нужды могут измениться, команда проекта поменяется, и дальше тыквы дело не пойдёт. При этом компании уже пришлось потратить несколько человеко-недель, чтобы понять сложную инфраструктуру, — а теперь нужно её поддерживать и вдобавок платить налоги.
На самом деле задачу можно решить проще. Практически любой мощный балансёр способен при отказе перенаправить на запасной бэкенд.
Вот что действительно важно на этапе стартапа:
- Максимально упростить инфраструктуру
- Использовать любую адекватную облачную базу — она нивелирует проблему, когда забыли настроить бэкапы или не замониторили ЦПУ
- Декомпозировать код
- Декларировать внешние API — о том, как это лучше сделать, смотрите в видео
Средний класс
Средний класс — это больше десяти разработчиков, которые ещё знают друг друга, и несколько бэкенд-сервисов.
Вот что осталось от предыдущего этапа развития — стартапа:
- Код хорошо декомпозирован, логические куски легко отселяются в соседние бинари
- Процесс типизации внешних запросов уже вшит в процесс разработки, и от этого есть понятный контракт между сервисами
Основные вызовы этого этапа — разобраться, что делать с базой и как разделить сервисы по ресурсам.
База. Бывает, что есть два сервиса: один пишет из базы, а второй — читает. Чтобы объяснить, почему это плохо, приведём пример из жизни.
Я работал с Apphost control plane, который читал конфигурации из репозитория и доставлял их под реальный API Gateway. Он был нормально декомпозирован, и каждая сущность не зависела от других. Но все они использовали одну базу, а это плохо:
- В случае плохого релиза нужно почти всегда чистить базу
- Интерфейс между сервисами плохо декларирован
- Если в базе есть relations, то каплинг между сервисами, скорее всего, смертельный
- База — единая точка отказа

Поэтому у каждого сервиса должна быть своя база.

Ресурсы. Когда бэкендов становится несколько, их нужно распиливать по ресурсам. Если этого не сделать, зависимые друг от друга фичи могут пострадать.
На этом этапе хороша любая эластичная среда. Идеально, если есть:
- Балансировка нагрузки
- Сервис дискавери
- Возможность декларативно описывать сервисы
Когда разработчики разделяют сервисы, как правило, возникает «проклятье» Gateway. Рассмотрим пример.
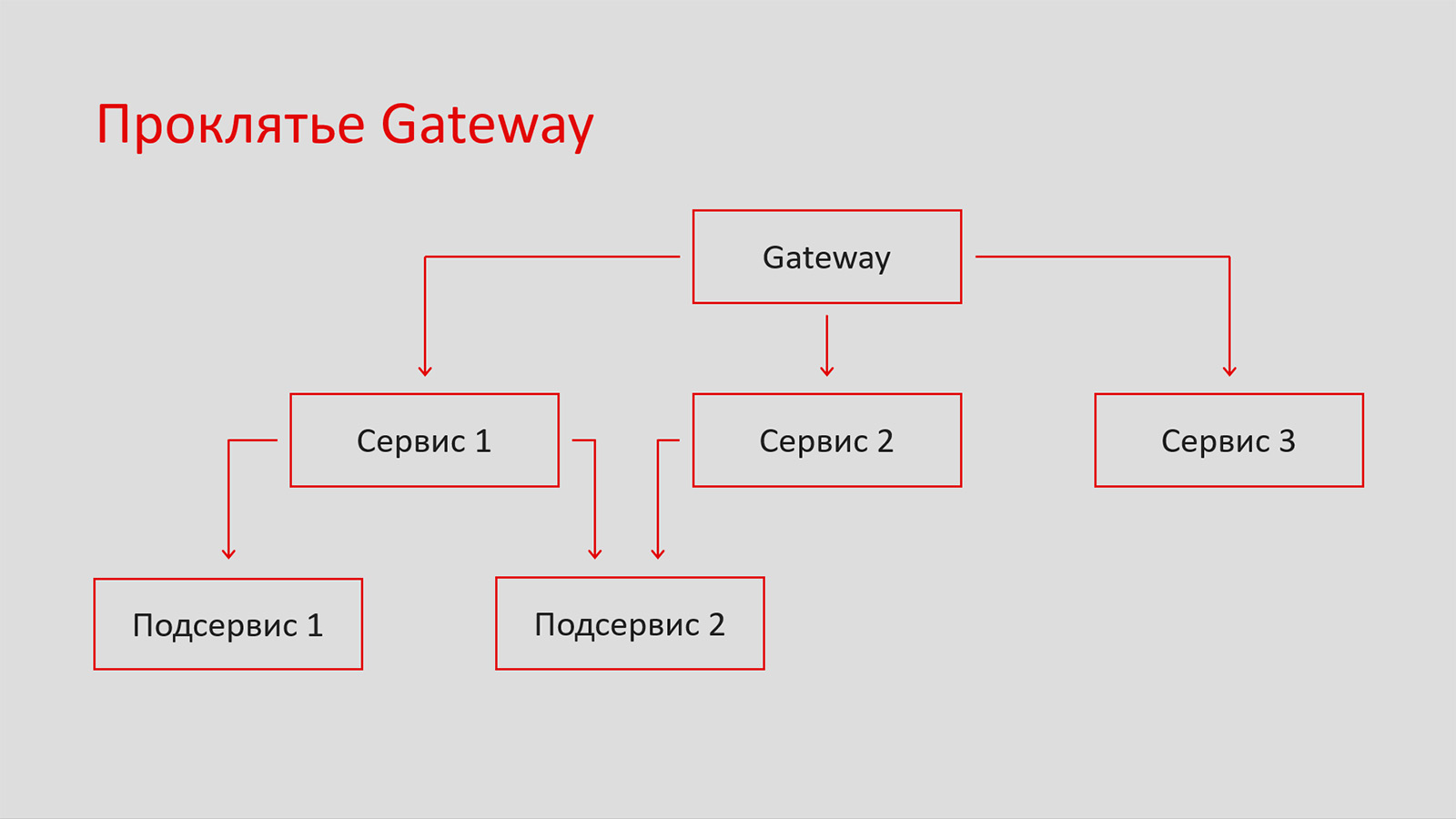
Сервис 1 принимает запрос пользователя, и в него легко добавить данные. Например, диаметрально противоположные подсервис 1 и сервис 3 хотят породить кусок JSON и сделать фичу для конечного пользователя. Скорее всего, это легко пробрасывается в Gateway — нужно только добавить поле в ответ.
Если использовать Gateway, через пару лет он будет настолько запутанным, что никто не будет знать, что там написано, почему и зачем. Поэтому в идеале Gateway — это просто инфраструктурный компонент, в котором нет бизнес-логики. Иначе его придётся переписывать.
Теперь представим, что внизу дерева микросервисов есть ещё и нейросетевая модель. На графике ниже видно скорость генерации текста ChatGPT — 5–10 секунд. Если ничего не показывать пользователю в это время, он уйдёт.

Появляется стриминг частичных результатов, а с ним и пачка проблем для Gateway:
- Схематизировать стриминговые API тяжелее
- Каждый сервис становится чуть-чуть стейтфул
- Балансировка стримов сложнее
Посмотрите доклад, чтобы узнать варианты решения этих проблем.
Корпорация
В корпорации разработчики перестают знать друг друга, проблема переписывания становится локальной, а главный фокус продукта направляется в сторону стабильности и масштабируемости.
После предыдущего этапа остались:
- Независимые сервисы, которые разделены по ресурсам и легко раздаются разным командам
- Доступ к базам данных, локализованный до одного сервиса
Вот какие трудности бывают на этом этапе:
- Дизастер-рекавери
- Непонятно, кто делает запросы и почему
- Тяжело планировать нагрузку и ресурсы
- Корпоративные боли: безопасность пользовательских данных, сертификации и ограниченный доступ к проду
Дизастер-рекавери. Пользователи отправляют запросы в cloud provider или anycast magic. Они приземляются в одном ДЦ или в одном регионе облака. В целом это хорошо для стэйбл-сервисов, но появляется проблема с базой — ведь она одна.
У дизастер-рекавери базы есть план А. Нужно взять базу, которая вас устраивает, и использовать её в нескольких ДЦ. В каком-то из них есть мастер — писать и читать можно из него. Если ДЦ или мастер не отвечает, нужно переходить в другой ДЦ. Для некоторых сервисов это работает, но слишком медленно.

Чтобы решить проблему медленного чтения и письма кросс-ДЦ, используют CAP-теорему:
- C — consistency — каждый живой участник системы отвечает одно и то же
- A — availability — каждый не упавший участник системы отвечает на запросы
- P — partition tolerance — система переживает потери и задержки сообщений между участниками
Выбирать приходится между двух систем — PC и PA. Лучшее, что можно купить: P + C + 0,99...9 × A.

Когда один сервис обращается к одной базе, базы распадаются на спектры. И когда компания делает шаг в сторону корпорации, она может выбирать базу из расчёта нужд одного сервиса и не думать о консистентности.
Запросы и ресурсы. Появляются такие корпоративные вопросы:
- «Кто налил 10 000 RPS?» — нужно понять, почему пришёл трафик
- «Куда уходят ресурсы?» — нужно объяснить руководителям, куда уходят деньги. Например, почему именно такую сумму платят cloud-провайдеру
Чтобы решить эти проблемы, можно использовать сервис-манифест — место, в котором написано всё про ваш сервис. Он может выглядеть так.

В сервис-манифесте указано:
- Название сервиса
- Базы данных
- API-схема
- Инсталляции и ресурсы
- Консьюмеры
Когда появляются сервис-манифесты, проблема про 10 000 RPS становится неактуальной за счёт квот. А проблема ресурсов всё ещё остаётся немного нераскрытой. Поэтому, как только потребители задекларированы, можно делать chargeback. То есть заключить контракт:
1K rps = X cpu + Y ram
Когда кто-то будет спрашивать о тратах, вы сможете говорить, что у вас есть потребители, и озвучивать цену. Если все согласны с контрактом, проблема решена. Если нет — появляется заказ на оптимизацию.
Заключение
Кратко, на что стоит обратить внимание на каждом этапе эволюции компании.
Стартапам
- Не переусложнить инфраструктуру
- Взять облачную базу
- Задекларировать API
- Декомпозировать код
Компаниям среднего класса
- Расселиться по ресурсам
- Разделить базы данных
Корпорациям
- Смотреть на нужды микросервиса при расселении на несколько ДЦ
- Внедрить сервис-манифесты