ML-платформа и её компоненты
ML-платформа даёт:
- Гибкость. ML-платформа позволяет выбирать и интегрировать необходимые бизнесу и разработчикам инструменты для решения ML-задач.
- Снижение стоимости эксплуатации. Для ML-платформы покупают серверы, которые доступны всем разработчикам. Не нужно приобретать их отдельно для каждой команды.
- Интеграция с внутренними бизнес-процессами. Внутренняя платформа позволяет более тесно интегрироваться с инструментами и процессами компании с учётом бизнес-требований.
Задачи. На основе задач построено всё в платформе. Например, такие инструменты, как Airflow as a Service и Jupiter Notebooks as a Service.
Задачи в ML-платформе состоят из:
- Класса обслуживания
- Набора ресурсов
- Окружения задачи
- Времени работы задачи
Класс обслуживания. Задачи делятся на непрерываемые (on-demand) и вытесняемые (preemptible).
Непрерываемые задачи нужны, чтобы выполнить критичные вычисления или код и не прерывать их. Цикл задачи: создание, ожидание ресурсов в кластере, а затем — в квоте, запуск, работа и завершение.
Вытесняемые задачи нужны для управления ресурсами платформы. При поломке сервера запущенная прерываемая задача фейлится. Именно поэтому в компании чаще используют вытесняемые задачи, которые в любой момент сохраняют состояние, чтобы не перезапускаться заново.
Чтобы preemptible-задачи чаще использовали в платформе, в Тинькофф дают возможность запускать их на весь кластер. При этом невытесняемые задачи могут занять ресурсы только в квоте, чтобы их было гораздо меньше, чем вытесняемых.
Набор ресурсов. Для описания задачи нужно сказать, сколько ресурсов ей потребуется. Например, количество CPU, GPU и RAM. В платформе это называется Flavor — имя ограниченного набора ресурсов задачи. Например, HeavyRAM или ManyCPU. Они используются для контроля над нагрузками на кластер, улучшения утилизации и контроля потребления ресурсов.
Окружение. Для описания задачи, её окружения и способа выполнения используют один или несколько Docker-образов. Они делают платформу универсальной — позволяют запускать любую логику, а не только ML-задачи.
Время работы. Задача должна завершаться, чтобы не занимать ресурсы кластера и приносить результат: готовую модель, чекпойнт, сохранённые данные. Именно поэтому время работы задачи ограничивают с помощью тайм-аута, после завершения которого её закрывают.
Особенности нагрузок на ML-платформе
В отличие от обычных нагрузок на платформах в рантайме нагрузка в ML-платформе имеет свои особенности:
- Ограничение во времени. В продакшен обычно запущены постоянно работающие сервисы, а в ML это batch-задачи, которые ограничены по времени.
- Необходимость большого числа вычислительных ресурсов. Соотношение количества ресурсов зависит от типа задачи. Например, команда рискового скоринга обрабатывает много данных, и у них достаточно простые модели, которым не нужен GPU. Именно поэтому они используют Flavor HeavyRAM c 800 GB RAM, 4 CPU и 0 GPU.
Команды Тинькофф, которые обучают навыки для виртуального помощника Олега, обрабатывают много данных на достаточно сложных моделях, поэтому они используют Flavor с 800 GB GPU, 16 CPU и 8 GPU NVIDIA A100. - Обработка большого количества данных. Задаче нужно обрабатывать несколько терабайт данных, поэтому диски на платформе должны иметь высокую скорость, чтобы задача выполнялась быстрее.
- Хранение состояния. Задачи должны хранить не только состояние, но и обученную модель и артефакты.
Исходные данные. Для создания платформы с такими особенностями использовали Slurm-кластер из множества узлов. Slurm — workload-менеджер, который позволяет запускать задачи на «голом железе».
Изначально были:
- Сложная непрозрачная система различных очередей для приоритизации задач
- Квотирование с гранулярностью в один узел из кластера под тенант
- Отсутствие сетевых политик
Kubernetes
Разработчики выбрали Kubernetes, поскольку он закрывал все необходимые потребности.
Особенности Kubernetes:
- Простое управление сетевыми политиками.
- Observability всего кластера.
- Хранилище состояния кластера. Можно добавлять или удалять ноды и без проблем мигрировать мастеров кластера.
- Масштабирование.
- Развитое комьюнити и хорошая документация. Более быстрое time-to-market по сравнению со Slurm.
- Огромное количество кастомных Kubernetes Operator в опенсорсе.
- Экспертиза внутри банка и вовне.
Реализация. Изначально использовали batch/Job — интегрированный внутри Kubernetes инструментарий. Он запускает batch-задачи, которые выполняются и завершаются. Разработчики сами работали в новом кластере, и у них не возникало проблем. Затем решили переключить команду, которая предсказывает временные ряды.
Разработчики обнаружили проблемы:
- Дедлайны задач. Задачи команды, которая предсказывает временные ряды, завершались до того, как команда запускала их, или посреди работы останавливались и фейлились. Kubernetes считал, что как только задача создана, её дедлайн уже считается. Даже если она не была запущена.
- Вытеснение задач. Preemptible-задачи не вытесняются и занимают ресурсы. Вытеснение в текущей схеме эквивалентно удалению пода задачи и приводит к её фейлу.
- Утилизация. Kubernetes-планировщик настроен на высокую доступность и не умеет максимально паковать ресурсы. Нагрузка аллоцируется по всем узлам, что приводит к низкой общей утилизации ресурсов в кластере. Чем больше распределены ресурсы, тем хуже задачи умещаются на узлах и дольше ждут освобождения достаточных ресурсов.
- Отсутствие квотирования. Нет лимита потребления ресурсов проектов — один проект может занять весь кластер. Без гарантированных ресурсов задача может не запуститься вовремя. На основе платформы нельзя строить продакшен-расчёты, чувствительные ко времени выполнения.
Собственный Kubernetes-оператор
Для решения проблем в Тинькофф написали свой Kubernetes-оператор.
- Проблемы с дедлайнами задач. С помощью Kubernetes-оператора разработчики запускают задачу в кластер только тогда, когда для неё есть ресурс.
- Проблемы с вытеснением задач. Kubernetes-оператор сам выбирает, какую задачу вытеснить для запуска текущей.
- Отсутствие квотирования. Задачу будут запускать в кластер, только если в нём и в квоте достаточно ресурсов.
Проблема утилизации. Kubernetes-оператор не решал проблему утилизации. Для этого сделали свой планировщик на базе Kubernetes 1.25 — внутри пода в Kubernetes указали имя планировщика, который им управляет. В этой версии оркестратора есть стратегия RequestedToCapacityRatio. Она пытается поставить задачу на тот узел, на котором максимально использует имеющиеся ресурсы.
Результат:
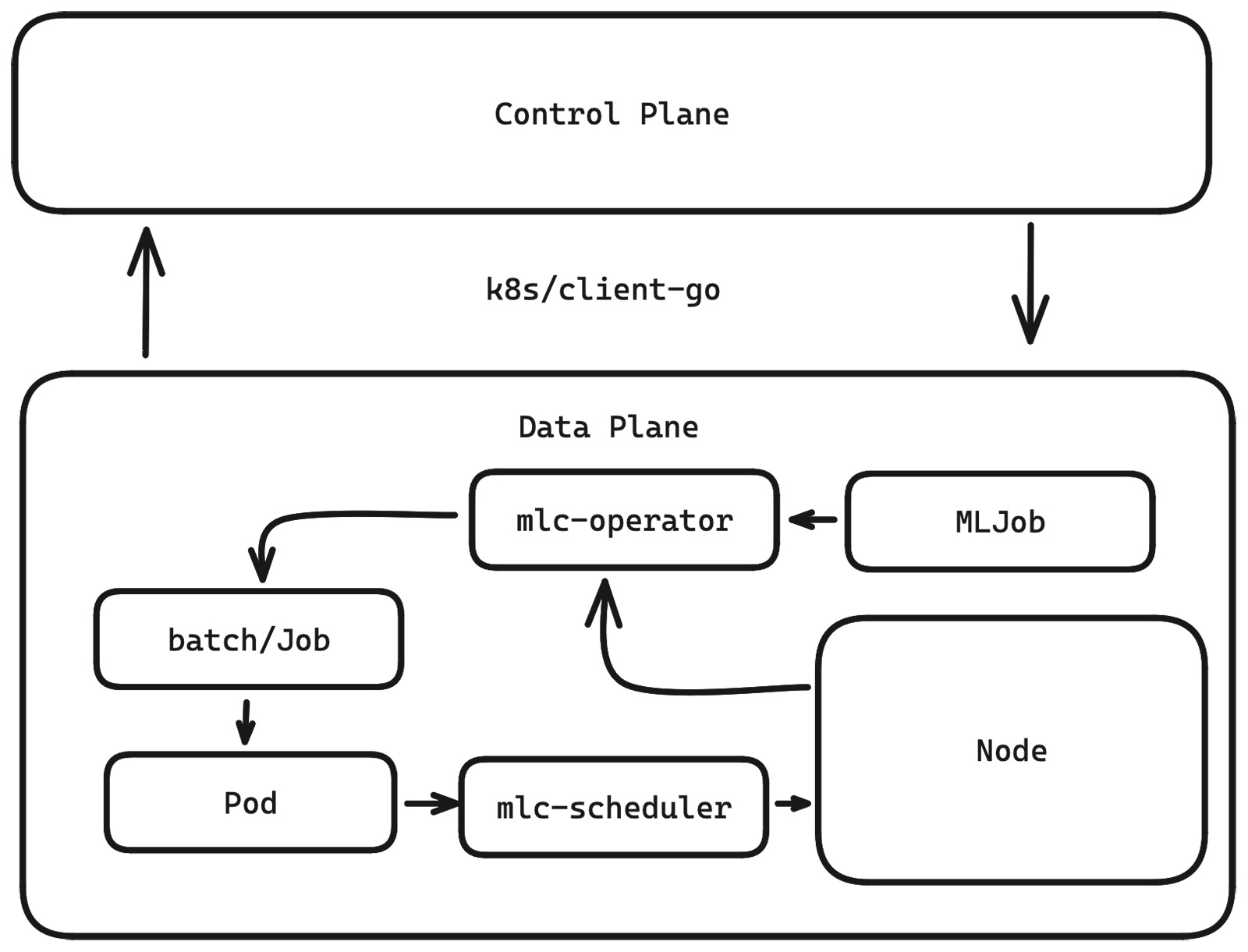
Можно допиливать свою логику на стороне оператора и добавлять более сложные кастомные решения.
Также появился мониторинг более высокого уровня, благодаря которому понятно состояние кластера: запускаются ли задачи и как это происходит.
Мониторинг
- Мониторинг кластера. На верхнем графике стандартный мониторинг, который иллюстрирует состояние кластера. Горбы на графиках показывают, что ML-инженеры выполняют задачи.
Нижние графики отражают состояние по типам ресурсов: CPU, GPU и RAM. Это помогает оценить количество свободных ресурсов в кластере и решить, стоит ли скелиться.
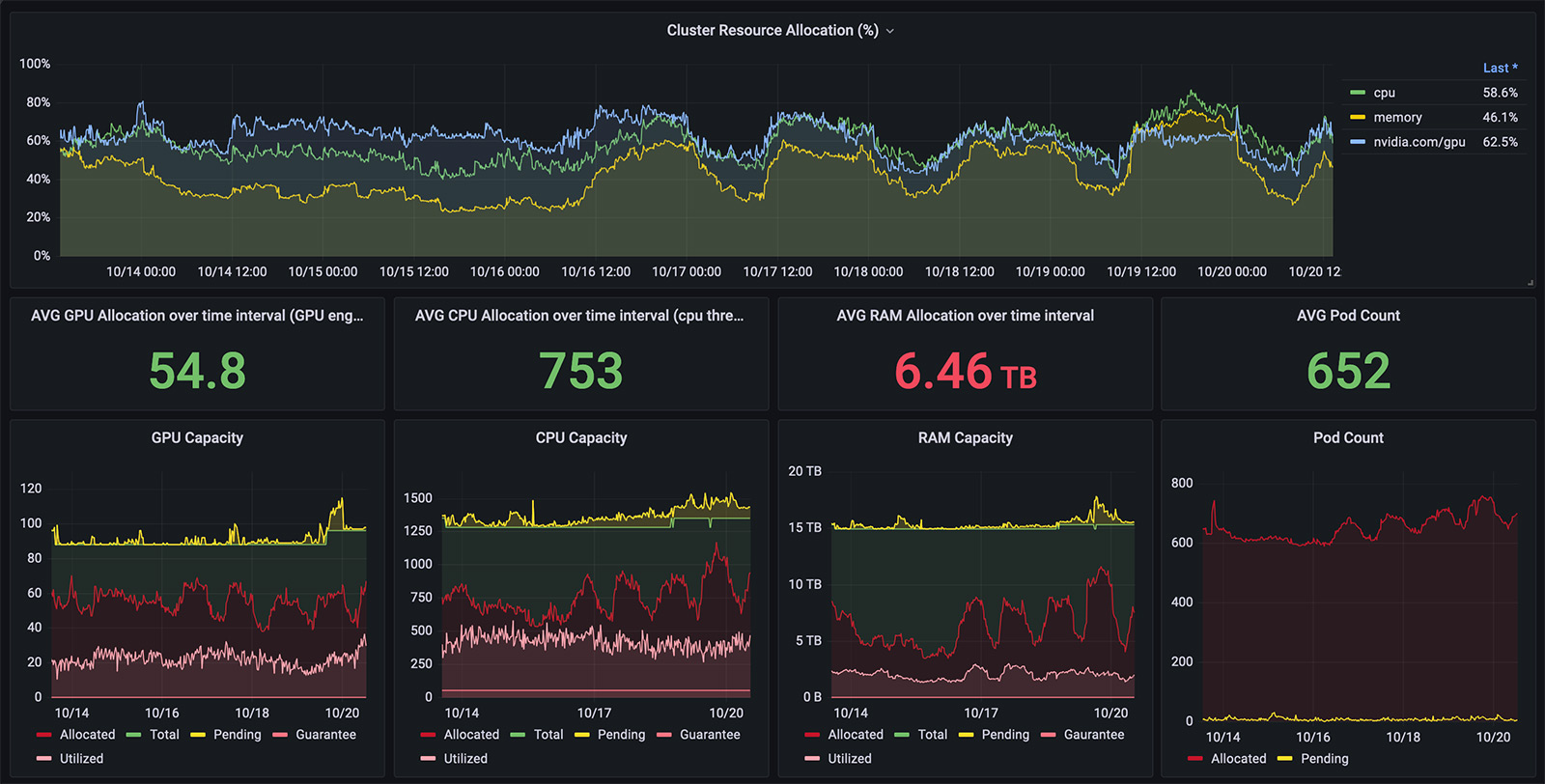
- Графики, которые показывают потребление ресурсов различными проектами. ML-платформа компании мультитенантная. Благодаря графикам разработчики понимают, сколько ресурсов потребляет каждый проект, и при необходимости могут повысить квоту.
- Графики по типам задач. Помимо on-demand и preemptible, на платформе запускаются задачи, которые используются для Airflow as a Service и Jupiter Notebooks as a Service. С помощью графиков в Тинькофф понимают, как часто это происходит и насколько выгодно использовать функционал платформы.
- График по квотированию. Показывают, насколько заняты ресурсы в квоте и сколько ожидают её освобождения. Это помогает понимать, с чем связано ограничение: с квотой или состоянием кластера.
В платформе появились проблемы с планированием ресурсов и производительностью.
Проблемы планирования ресурсов:
- Несколько независимых планировщиков в кластере. Для планирования ресурсов они используют состояние кластера. Если оно запаздывает у одного из планировщиков, к другому приходит под и занимает ноду. Затем к первому планировщику также приходит под, который ещё не знает, что нода занята, и пытается поставить на неё задачу.
Появляется ошибка Unexpected Admission error. Чтобы избавиться от неё, нужно выделить каждому планировщику свой сет нод, с которым будет работать только он. - Дублирование логики планировщика в операторе. Оператор выполняет те же функции, что и планировщик: определяет, сколько в кластере ресурсов и есть ли возможность запустить задачу. Дублируется сложный код, который в то же время плохо тестируется. Так как нельзя импортировать модули планировщика, можно написать только свой код, который будет это делать.
- Простой кластера. Это произойдёт, если по ошибке оператор запустит задачу в кластер, но для неё не будет места. Неизвестно, на какую ноду в операторе в итоге упадёт задача. Именно поэтому нельзя будет создать новые задачи, пока эта не приземлится на узел.
Проблемы производительности:
- Размер очереди важен. В Kubernetes операторы выгружают все данные в память, что может привести к OOM. Обработка очереди в памяти приводит к линейному росту задержки планирования ресурсов.
- Квотирование в Kubernetes-операторе может ошибаться. Сделать хорошую логику квотирования непросто, а тестировать и поддерживать её ещё сложнее.
- Вытеснение в Kubernetes-операторе. На самом деле правильнее делать вытеснение на стороне планировщика. Оператор должен создавать ресурс и транслировать его в другие ресурсы Kubernetes, но в данном случае он выполнял несколько функций.
Опенсорсное решение
В команде решили внедрить готовый движок и сначала определили критерии:
- Поддерживаемость. При необходимости можно вносить правки в код и настраивать решение под себя.
- Простота использования. Движок легко закатить в кластер и добавлять новые версии. Желательно, чтобы он имел понятные метрики. При этом команда хотела привнести минимум новых технологий.
- Конфигурируемый планировщик. Разработчики Тинькофф хотели максимально утилизировать ресурсы и улучшать UX пользователей, уменьшая задержку на запуск задач.
- Квотирование с гарантированием ресурсов.
Какие опенсорсные решения рассматривали:
- Kueue
- Apache YuniKorn
- Volcano.sh
У Kueue был простой планировщик, который не подходил разработчикам. Apache YuniKorn для работы с Kubernetes нуждался в дополнительной прослойке, которая бы транслировала одни объекты в другие. Её сложно реализовать.
В итоге разработчики выбрали Volcano.sh. Это нативное для Kubernetes решение, которое создано для обработки ML-задач. Его можно расширять плагинами и допиливать, потому что оно написано нa Go, который также используют в команде разработки.
Результат:
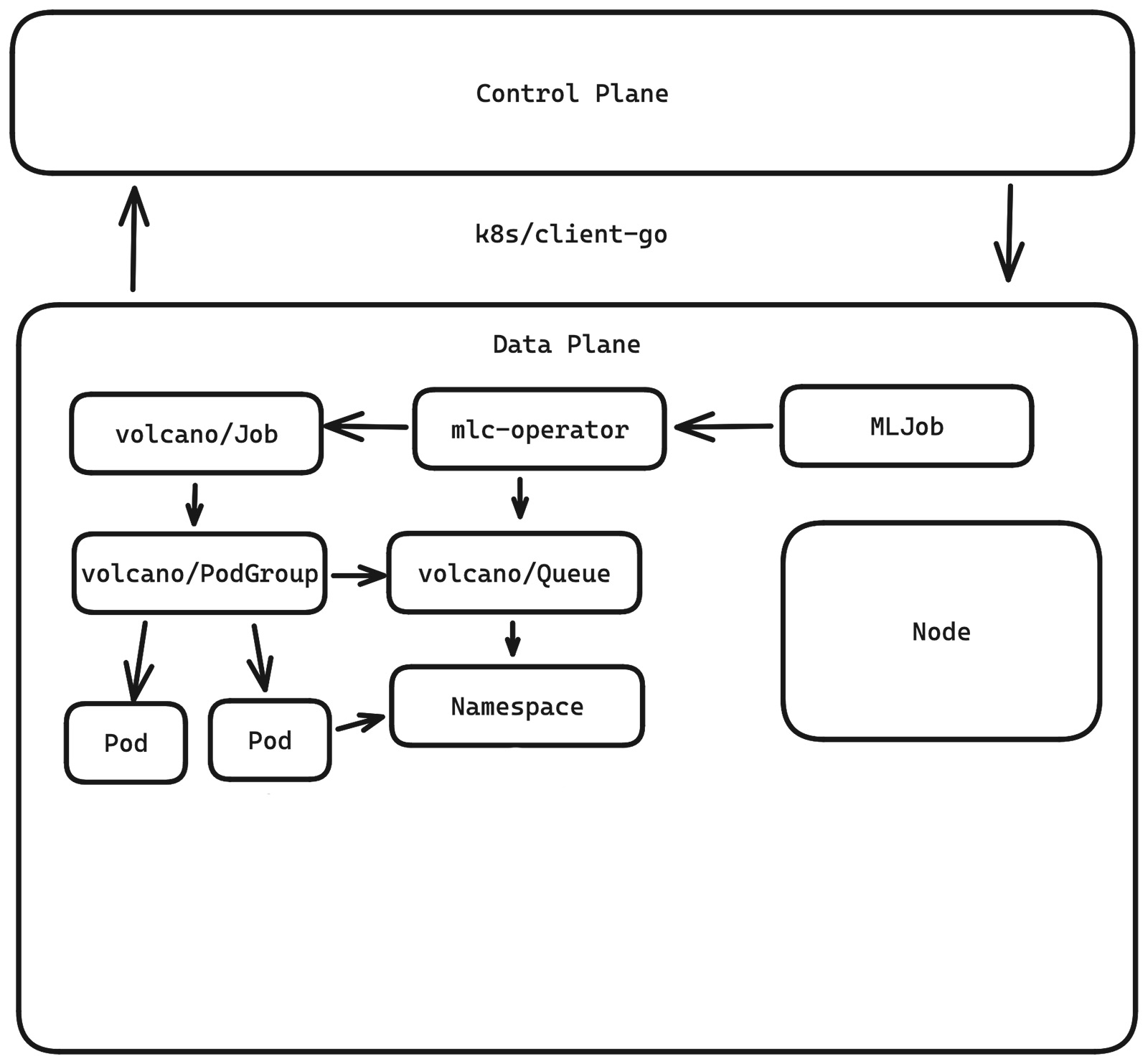
В схеме задействован Кubernetes-оператор, потому что разработчики хотели сохранить мониторинг платформы. Они могут легко заменить Volcano.sh на Apache YuniKorn и создать что-то на его базе, при этом никак не меняя логику работы Control Plane и Data Plane.
Проблемы Volcano.sh:
- Вытеснение. Volcano.sh мог вытеснить вытесняемую задачу только в рамках одного проекта. При этом он должен был уметь заменять любую вытесняемую задачу, когда приходит невытесняемая.
- Квотирование. Чтобы иметь гарантированные квоты для каждого проекта, нужно создавать отдельную Volcano.sh-очередь. Она аллоцирует под собой ресурсы и отдаёт их задачам внутри очереди.
После доработки Volcano.sh получили:
- Гарантированные квоты. Они позволяют гарантировать каждому проекту определённое количество всегда доступных ресурсов, даже если кластер переполнен.
- Приоритетное вытеснение задач. Каждый класс задач имеет свой приоритет. Также есть приоритеты внутри класса, которые позволяют управлять очерёдностью запуска задач и вытеснением между приоритетами.
- Буст утилизации ресурсов. Scheduler у Volcano.sh имеет много возможностей и плагинов. При правильной настройке он позволяет делать оптимизации, которые на порядок улучшают утилизацию ресурсов в кластере. Разработчики продолжают дорабатывать планировщик Volcano.sh для решения своих задач.
Планы на будущее
- Внедрить мультиподное обучение для обучения LLM и использования MPI.
- Улучшать планировщик, чтобы улучшать утилизацию и снижать время ожидания запуска задач. Для этого разработчики продолжат изучать плагины планировщика Volcano.sh и подходы к планированию ресурсов.
- Переносить все правки Volcano.sh в upstream проекта в опенсорсе.